Hadoop之Hive
Hive的安装
常用命令
:
初始化
1
[root@master hive-2.3.3]# schematool -initSchema -dbType derby
查看数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30查看有哪些数据库
show databases;
OK
default
Time taken: 4.746 seconds, Fetched: 1 row(s)
进入到那个数据库
use default;
OK
Time taken: 0.023 seconds
show tables;
OK
Time taken: 0.055 seconds
create table student(id int,name string);
OK
Time taken: 0.827 seconds
show tables;
OK
student
Time taken: 0.019 seconds, Fetched: 1 row(s)
desc student;
OK
id int
name string
Time taken: 0.245 seconds, Fetched: 2 row(s)
select * form student;
FAILED: ParseException line 1:9 missing EOF at 'form' near '*'
select * from student;
OK
Time taken: 1.413 seconds
quit;
YkNWIr-_g6G8
1 | hive -e "select * from bigdata.student;" |
不进入Hive的命令行窗口就可以执行SQL语句
1 | [root@master test]# hive -f hive-seclet.sql |
不进入Hive的命令行窗口就可以执行文件中的SQL
1 | hive (default)> quit; |
exit:先提交数据,然后退出
quit:不提交数据,直接退出。
1 | hive (default)> dfs -ls /hive; |
使用Hive的命令行窗口执行HDFS文件系统的查询
1 | hive (default)> ! ls /opt; |
使用Hive的命令窗口查看本地文件系统的文件和目录
1 | [root@master ~]# cat .hivehistory |
在本地文件系统中会存储hive中执行的命令的历史(在当前用户主目录)
Hive中的数据类型
基本数据类型
| Hive数据类型 | 长度 | Java中对应的类型 | example |
|---|---|---|---|
| tinyint | 1字节 | byte | 20 |
| int | 4字节 | int | 111111 |
| smallint | 2字节 | short | 222 |
| bigint | 8字节 | long | 111111111111 |
| boolean | 布尔 | boolean | true |
| float | 4字节 | float | 1.1 |
| double | 8字节 | double | 1.11111111 |
| string | string | “hhahaha”,’hhh’ | |
| timstamp | 日期类型 | Timestamp | |
| date | 日期类型 | date | |
| binary | 字节数组 |
- 集合类型
- |数据类型|描述|
|—|—|
|struct|比如某一列的数据类型是struct{first string,sc string,th int},.sc来拿到第2个元素|
|map|一组键值对集合,[‘键名’]|
|array|数组,[‘11’,’222’,’33’],[1],表示拿到第二个元素|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 数据
John Doe,100000.0,Mary Smith_Todd Jones,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,1 Michigan Ave._Chicago_1L_60600
Tom Smith,90000.0,Jan_Hello Ketty,Federal Taxes:0.2_State Taxes:0.05_Insurance:0.1,Guang dong._China_0.5L_60661
# 创建表
CREATE TABLE employees(
name STRING,
sa1ary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING, FLOAT>,
address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '_'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
# 查询
hive (list)> select * from employees;
OK
employees.name employees.sa1ary employees.subordinates employees.deductions employees.address
John Doe 100000.0 ["Mary Smith","Todd Jones"] {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} {"street":"1 Michigan Ave.","city":"Chicago","state":"1L","zip":60600}
Tom Smith 90000.0 ["Jan","Hello Ketty"] {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1{"street":"Guang dong.","city":"China","state":"0.5L","zip":60661}
Time taken: 0.131 seconds, Fetched: 2 row(s)
hive (list)> select subordinates[1], deductions['Federal Taxes'],address.city from list.employees;
OK
_c0 _c1 city
Todd Jones 0.2 Chicago
Hello Ketty 0.2 China
Time taken: 0.121 seconds, Fetched: 2 row(s)
- 类型之间的转换
- 和Java类型,有自动类型转换,int——>double
强制转换:cast
SQL 语法
- SQL 不区分大小写
- SQL 可以写成一行也可以写成多行
- SQL 的关键字不能分行来写,不能拆开,不能简写
- 增加缩进
- SQL 不要全部写成一行,字句一定要分开写
DDL 的简单操作
创建数据库
:
在HDFS上创建数据库:warehouse/wangguo.db
1
hive (bigdata)> create database wangguo;
建议:以后加上if not exists判断
1
2
3
4
5hive (bigdata)> create database wangguo;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database wangguo already exists
hive (bigdata)> create database if not exists wangguo;
OK
Time taken: 0.011 seconds![image_1ckf1iom41vkp1h0dm0f9j2oil9.png-40.3kB][1]
修改数据库
: alter可以修改数据库的属性
1
hive (bigdata)> alter database wangguo set dbproperties('createtime'='20180808');
注意:数据库中的一些属性可以修改,但是数据库的名字和数据库所在目录不可更改。
查看数据库
:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#显示所有的数据库
hive (default)> show databases;
OK
database_name
bigdata
default
lisi
wangguo
Time taken: 4.259 seconds, Fetched: 4 row(s)
# 条件查询数据库
hive (default)> show databases like 'li*';
OK
database_name
lisi
Time taken: 0.047 seconds, Fetched: 1 row(s)
# 查询数据库的详细信息
hive (default)> desc database bigdata;
OK
db_name comment location owner_name owner_type parameters
bigdata hdfs://master:9000/hive/warehouse/bigdata.db root USER
Time taken: 0.026 seconds, Fetched: 1 row(s)
# 使用数据库
hive (default)> use bigdata;
OK
Time taken: 0.02 seconds
hive (bigdata)>
删除数据库
:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 删除数据库
hive (bigdata)> drop database if exists lisi;
OK
Time taken: 0.19 seconds
# 再次查看所有数据库
hive (bigdata)> show databases;
OK
database_name
bigdata
default
wangguo
Time taken: 0.009 seconds, Fetched: 3 row(s)
# 删除非空数据库
hive (bigdata)> drop database bigdata;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database bigdata is not empty. One or more tables exist.)
# 强制删除非空数据库
hive (bigdata)> drop database bigdata cascade;
OK
Time taken: 1.539 seconds
# 再次查看所有数据库
hive (bigdata)> show databases;
OK
database_name
default
wangguo
Time taken: 0.009 seconds, Fetched: 2 row(s)
创建表
:
[建表语法][2]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ... )]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement];
说明:
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
- EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
- COMMENT:为表和列添加注释。
- PARTITIONED BY 创建分区表
- CLUSTERED BY 创建分桶表
- SORTED BY 不常用
- 用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
- STORED AS 指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。- LOCATION :指定表在 HDFS 上的存储位置。
- LIKE 允许用户复制现有的表结构,但是不复制数据。
- TBLPROPERTIES表的属性
- AS select_statement将其他查询结果作为这个表的数据导入
- 内部表
- 默认创建的表都是所谓的内部表,有时也被称为管理表。因为这种表,Hive 会(或多或少地)控制着数据的生命周期。Hive 默认情况下会将这些表的数据存储在由配置项 hive.metastore.warehouse.dir(例如,/hive/warehouse)所定义的目录的子目录下。 当我们删除一个内部表时,Hive 也会删除这个表中数据。内部表不适合和其他工具共享数据。
创建内部表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34# 创建表基本语法
hive (wangchen)> use wangchen;
OK
Time taken: 0.034 seconds
hive (wangchen)> create table if not exists teacher(id int,name string)
> row format delimited fields terminated by '\t'
> stored as textfile
> location '/wang/wangchen/teacher';
OK
Time taken: 0.11 seconds
hive (wangchen)> show tables;
OK
tab_name
teacher
Time taken: 0.026 seconds, Fetched: 1 row(s)
# 根据查询结果创建表
hive (wangchen)> create table if not exists student2 as select * from student;
Total MapReduce CPU Time Spent: 1 seconds 980 msec
OK
student.id student.name
Time taken: 35.467 seconds
hive (wangchen)> select * from student2;
OK
student2.id student2.name
10001 zhangsan
10002 lisi
10003 kongchenlei
10004 zhoushengnan
Time taken: 0.442 seconds, Fetched: 4 row(s)
# 根据已经存在的表创建表
create table if not exists student2 as select * from student;
# 查询表的类型
desc formatted student3;
- 外部表
- 创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。Hive 并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
1 |
|
- 分区表
- 分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
创建分区表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 创建分区表的基本语法
create table student(id int,name string)
partitioned by (day string comment 'dddd')
row format delimited fields terminated by '\t';
# 加载数据到分区表中
load data local inpath 'wuqing' into table student partition (day='03');
# 查询分区表中数据-单分区
select * from student where day='02';
# 查询分区表中数据-多分区
# 增加分区
alter table student add partition(day='05');
# 增加多分区
# 删除分区
alter table student drop partition (day='03');
# 查看分区
# 查看分区表的结构
desc formatted student;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 创建二级分区
create table teacher(id int,name string)
partitioned by(month string,day string)
row format delimited fields terminated by '\t';
# 加载数据
load data local inpath 'wuqing' into table teacher partition(month='11',day='02');
# 查询
select * from teacher;
# 分区数据关联的三种方式
# 方式一:先上传,后修复
dfs -put wuqing /user/hive/warehouse/bigdata.db/student/day=04;
select * from student;
OK
1001 qwqwerq 02
1002 adfasd 02
1003 sadfas 02
1001 qwqwerq 05
1002 adfasd 05
1003 sadfas 05
1001 qwqwerq 05
1002 adfasd 05
1003 sadfas 05
Time taken: 0.151 seconds, Fetched: 9 row(s)
执行修复
msck repair table student;
OK
Partitions not in metastore: student:day=04
Repair: Added partition to metastore student:day=04
Time taken: 0.368 seconds, Fetched: 2 row(s)
select * from student;
OK
1001 qwqwerq 02
1002 adfasd 02
1003 sadfas 02
1001 qwqwerq 04
1002 adfasd 04
1003 sadfas 04
1001 qwqwerq 05
1002 adfasd 05
1003 sadfas 05
1001 qwqwerq 05
1002 adfasd 05
1003 sadfas 05
Time taken: 0.178 seconds, Fetched: 12 row(s)
# 方式二:先上传,后修改
dfs -mkdir /user/hive/warehouse/bigdata.db/student/day=06;
dfs -put wuqing /user/hive/warehouse/bigdata.db/student/day=06;
alter table student add partition(day='06');
# 方式三:先上传,后加载
- 修改表
1
2
3
4
5
6
7
8# 表的重命名
alter table student rename to student100;
# 添加列
alter table student100 add columns(haha string);
# 更改列:是将某一列更改了
alter table student100 change column hehe haha string;
# 替换列:后面跟的是新的列名
alter table student100 replace columns(ids int,names string);
- 删除表
1
2# 删除操作
drop
DML操作
数据导入
:
- Load模式
1
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- load data:表示加载数据
- local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
- inpath:表示加载数据的路径
- into table:表示加载到哪张表
- tablename:表示具体的表
- overwrite:表示覆盖表中已有数据,否则表示继续添加
- partition:表示上传到指定分区
1
2
3
4
5
6
7
8
9
## 加载数据到Hive
hive (bigdata)> create table student(id int,name string) row format delimited fields terminated by '\t';
OK
Time taken: 0.495 seconds
hive (bigdata)> load data local inpath '/opt/test/student' into table bigdata.student;
Loading data to table bigdata.student
OK
Time taken: 1.131 seconds
hive (bigdata)> dfs -put /opt/test/student /aaa.txt;
insert模式
1
2INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;1
2
3
4
5
6
7
8
9
10
11
12# 基本insert into
hive (bigdata)> insert into table student values('10006','lallalalalalla');
hive (bigdata)> insert into table student select * from wangchen.teacher;
# 基本的insert overwrite
hive (bigdata)> insert overwrite table student select * from wangchen.teacher;
# 将一个表中的数据插入到多个表中
hive (bigdata)> from wangchen.teacher
> insert overwrite table student select *
> insert overwrite table student1 select *;
hive (bigdata)> from student
> insert overwrite table student_part partition(day='20180813') select *
> insert overwrite table student_part partition(day='20180814') select * ;as select模式
1
hive (bigdata)> create table student2 as select * from student;
Location模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17hive (bigdata)> create table student3(id int,name string)
> row format delimited fields terminated by '\t'
> location '/haha/lala/hehe';
OK
Time taken: 0.059 seconds
hive (bigdata)> select * from student3;
OK
student3.id student3.name
Time taken: 0.105 seconds
hive (bigdata)> dfs -put /opt/test/student /haha/lala/hehe;
hive (bigdata)> select * from student3;
OK
student3.id student3.name
10001 zhangsan
10002 lisi
10003 kongchenlei
10004 zhoushengnanImport模式
1
2## 导入的路径必须是export的路径
hive (bigdata)> import table student from '/opt/export';
数据导出
:
insert模式
1
2
3
4
5
6
7
8
9
10
11
12## 导出到本地
hive (bigdata)> insert overwrite local directory '/opt/test/export' select * from student1;
hive (bigdata)> insert overwrite local directory '/opt/test/export'
> row format delimited fields terminated by '\t'
> collection items terminated by '\n'
> select * from student1;
## 导出到HDFS上
hive (bigdata)> insert overwrite directory '/opt/test/export'
> row format delimited fields terminated by '\t'
> collection items terminated by '\n'
> select * from student1;export模式
1
2## 导出路径必须为不存在的
hive (bigdata)> export table student1 to '/opt/export/';dfs -get模式
1
hive (bigdata)> dfs -get /hive/warehouse/bigdata.db/student1/000000_0 /opt/test/export/aaa.txt;
hive -e 模式
1
[root@master export]# hive -e 'select * from bigdata.student1;' > /opt/test/export/e.txt;
Sqoop 导出
- 数据删除
- 注意:Truncate 只能删除管理表(内部表),不能删除外部表中数据
1
hive (bigdata)> truncate table student1;
DQL操作
- 基本查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16hive (bigdata)> select * from student3;
OK
student3.id student3.name
10001 zhangsan
10002 lisi
10003 kongchenlei
10004 zhoushengnan
Time taken: 0.121 seconds, Fetched: 4 row(s)
hive (bigdata)> select id from student3;
OK
id
10001
10002
10003
10004
Time taken: 0.12 seconds, Fetched: 4 row(s)
- 常用函数
1
2
3
4
5
6
7
8+ - * / % & | ^ ~
hive (bigdata)> select score+10 from chengji;
hive (bigdata)> select count(*) count from chengji;
hive (bigdata)> select max(score) max_score from chengji;
hive (bigdata)> select sum(score) sum_score from chengji;
hive (bigdata)> show functions;
hive (bigdata)> select * from chengji limit 4;
hive (bigdata)> select * from chengji limit 3,4;
条件查询
:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
hive (bigdata)> select * from chengji where score > 60;
OK
chengji.id chengji.name chengji.kemu chengji.score
1001 张三 语文 99
1002 李四 语文 88
1003 张三 数学 88
1004 王五 英语 88
1005 哈哈 数学 100
1006 李四 数学 94
1008 李四 英语 100
hive (bigdata)> select * from chengji where score>50 and score<80;
OK
chengji.id chengji.name chengji.kemu chengji.score
1012 哈哈 语文 60
Time taken: 0.126 seconds, Fetched: 1 row(s)
hive (bigdata)> select * from chengji where score between 50 and 80;
OK
chengji.id chengji.name chengji.kemu chengji.score
1012 哈哈 语文 60
Time taken: 0.106 seconds, Fetched: 1 row(s)
hive (bigdata)> select * from chengji;
OK
chengji.id chengji.name chengji.kemu chengji.score
1001 张三 语文 99
1002 李四 语文 88
1003 张三 数学 88
1004 王五 英语 88
1005 哈哈 数学 100
1006 李四 数学 94
1007 张三 英语 20
1008 李四 英语 100
1009 王五 语文 40
1010 王五 数学 20
1011 哈哈 英语 44
1012 哈哈 语文 60
1013 lala hehe NULL
Time taken: 0.105 seconds, Fetched: 13 row(s)
hive (bigdata)> select * from chengji where score is null;
OK
chengji.id chengji.name chengji.kemu chengji.score
1013 lala hehe NULL
Time taken: 0.11 seconds, Fetched: 1 row(s)
hive (bigdata)> select * from chengji where score in(88,44);
OK
chengji.id chengji.name chengji.kemu chengji.score
1002 李四 语文 88
1003 张三 数学 88
1004 王五 英语 88
1011 哈哈 英语 44
Time taken: 0.105 seconds, Fetched: 4 row(s)
hive (bigdata)> select * from chengji where score in(88,44,66);
OK
chengji.id chengji.name chengji.kemu chengji.score
1002 李四 语文 88
1003 张三 数学 88
1004 王五 英语 88
1011 哈哈 英语 44
Time taken: 0.109 seconds, Fetched: 4 row(s)
hive (bigdata)> select * from chengji where score in(88,44,99);
OK
chengji.id chengji.name chengji.kemu chengji.score
1001 张三 语文 99
1002 李四 语文 88
1003 张三 数学 88
1004 王五 英语 88
1011 哈哈 英语 44
Time taken: 0.105 seconds, Fetched: 5 row(s)
- 模糊查询
- like,Rlike
- % : 代表任意字符(任意多个或0个)
- _ : 表示一个字符Rlike: Hive中对like的一个扩展,可以直接使用Java中正则表达式
1 | hive (bigdata)> select * from chengji where score like '9%'; |
- 逻辑运算符的应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28hive (bigdata)> select * from chengji where kemu='01' and score>60;
OK
chengji.id chengji.name chengji.kemu chengji.score
1001 01 01 99
1002 02 01 88
Time taken: 0.118 seconds, Fetched: 2 row(s)
hive (bigdata)> select * from chengji where kemu='01' or score>60;
OK
chengji.id chengji.name chengji.kemu chengji.score
1001 01 01 99
1002 02 01 88
1003 01 02 88
1004 03 03 88
1005 04 02 100
1006 02 02 94
1008 02 03 100
1009 03 01 40
1012 04 01 60
Time taken: 0.122 seconds, Fetched: 9 row(s)
hive (bigdata)> select * from chengji where kemu not in('01','02');
OK
chengji.id chengji.name chengji.kemu chengji.score
1004 03 03 88
1007 01 03 20
1008 02 03 100
1011 04 03 44
1013 lala hehe NULL
Time taken: 0.097 seconds, Fetched: 5 row(s)
分组查询
:
Group By语句
GROUP BY 语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25hive (bigdata)> select c.kemu,avg(c.score) avg_score from chengji c group by c.kemu;
OK
c.kemu avg_score
01 71.75
02 75.5
03 63.0
hehe NULL
hive (bigdata)> select c.kemu,max(c.score) max_score from chengji c group by c.kemu;
OK
c.kemu max_score
01 99
02 100
03 100
hehe NULL
Time taken: 26.277 seconds, Fetched: 4 row(s)
## 每个人成绩最高的科目
hive (bigdata)> select name,max(score) from chengji group by name;
name _c1
lala NULL
哈哈 100
张三 99
李四 100
王五 88Having 语句
having 与 where 不同点- where 针对表中的列发挥作用,查询数据;having 针对查询结果中的列发挥作用,筛选数据。
- where 后面不能写分组函数,而 having 后面可以使用分组函数。
- having 只用于 group by 分组统计语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15hive (bigdata)> select c.name,avg(c.score) avg_score from chengji c group by c.name;
OK
c.name avg_score
01 69.0
02 94.0
03 49.333333333333336
04 68.0
lala NULL
Time taken: 27.018 seconds, Fetched: 5 row(s)
hive (bigdata)> select c.name,avg(c.score) avg_score from chengji c group by c.name having avg_score>68;
OK
c.name avg_score
01 69.0
02 94.0
Time taken: 28.275 seconds, Fetched: 2 row(s)
- join操作
- Hive 支持通常的 SQL JOIN 语句,但是只支持等值连接,不支持非等值连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22## 使用join查询员工的信息:ID,姓名,部门名字,职位,薪资
hive (bigdata)> select y.id,y.name,b.name,y.zhiwei,y.xinzi from yuan y
> join bumen b on y.bumen=b.id;
## 内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会显示出来。
## 左外连接:将左侧都显示,右侧不满足条件的替换为null
hive (bigdata)> select y.id,y.name,b.name,y.zhiwei,y.xinzi from yuan y
> left join bumen b on y.bumen=b.id;
## 右外连接:将右侧显示,左侧不满足条件的替换为null
hive (bigdata)> select y.id,y.name,b.name,y.zhiwei,y.xinzi from yuan y
> right join bumen b on y.bumen=b.id;
## 满外链接:两个表都显示,不满足条件的都替换为null
hive (bigdata)> select y.id,y.name,b.name,y.zhiwei,y.xinzi from yuan y
> full join bumen b on y.bumen=b.id;
## 笛卡尔积连接(不要使用)
hive (bigdata)> set hive.mapred.mode='strict';
hive (bigdata)> set hive.strict.checks.cartesian.product=false;
hive (bigdata)> select y.id,y.name,b.name,y.zhiwei,y.xinzi from yuan y
> join bumen b;
- 排序查询
- 全排序(这个结果排序),部分排序(区内排序),二次排序(compareTo),辅助排序(组内排序)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19## 成绩表按照成绩升序排序(asc)
hive (bigdata)> select * from chengji order by score;
## 成绩表按照成绩降序排序(desc)
hive (bigdata)> select * from chengji order by score desc;
## 成绩表按照多列进行排序
hive (bigdata)> select * from chengji order by score,name;
hive (bigdata)> select * from chengji order by score desc,name asc;
## 部分内部排序(sort by)
hive (bigdata)> set mapreduce.job.reduces=4;
hive (bigdata)> select * from chengji sort by score desc;
## 分区排序
## distribute by:类似于MR中分区,先分区后排序.必须结合sort by 使用
hive (bigdata)> select * from chengji distribute by kemu sort by score desc;
## cluster by
## distribute by+ sort by 可以使用cluster by(只能按照升序)代替(排序的字段和分区的字段是一样的)
hive (bigdata)> select * from chengji cluster by kemu;
- 分桶操作
- 分区针对的是数据的存储目录;分桶针对的是数据文件。
- 分区
- 分区提供的是一级一级的目录,这个划分并没有任何的数据大小的限制,会导致某一个分区的数据量很大,某一个分区的数据量很小。
- 分桶
- 分桶是将数据文件直接分成若干份
分桶表数据存储
1
2
3
4
5
6
7
8
9
10## 创建分桶表
hive (bigdata)> create table student_bucket(id int,name string)
> clustered by(id) into 4 buckets
> row format delimited fields terminated by '\t';
## 直接导入数据,会发现并未分桶
hive (bigdata)> load data local inpath '/opt/test/student' into table student_bucket;
## 解决方案,设置并使用insert方式导入数据
hive (bigdata)> set hive.enforce.bucketing=true;
hive (bigdata)> insert into table student_bucket select * from student cluster by(id);分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive 可以通过对表进行抽样来满足这个需求。
select * from tablename tablesample(bucket x out of y on id);
y 必须是 table 总 bucket 数的倍数或者因子。hive 根据 y 的大小,决定抽样的比例。例如,table 总共分了 4 份,当 y=2 时,抽取(4/2=)2 个 bucket 的数据,当 y=8 时,抽取(4/8=)1/2个 bucket 的数据。
x 表示从哪个 bucket 开始抽取。例如,table 总 bucket 数为 4,tablesample(bucket 4 out of 4),表示总共抽取(4/4=)1 个 bucket 的数据,抽取第 4 个 bucket 的数据。
注意:x 的值必须小于等于 y 的值,否则会报错1
2
3
4
5
6hive (bigdata)> select * from student_bucket tablesample(bucket 2 out of 4 on id);
hive (bigdata)> select * from chengji_buck tablesample(bucket 4 out of 2 on id);
hive (bigdata)> select * from chengji_buck tablesample(bucket 1 out of 2 on id);
hive (bigdata)> select * from chengji_buck tablesample(bucket 4 out of 4 on id);
hive (bigdata)> select * from chengji_buck tablesample(bucket 4 out of 8 on id);
hive (bigdata)> select * from chengji_buck tablesample(bucket 1 out of 8 on id);百分比抽样
Hive 提供了另外一种按照百分比进行抽样的方式,这种是基于行数的,按照输入路径下的数据块百分比进行的抽样。
注意:这种抽样方式不一定适用于所有的文件格式。另外,这种抽样的最小抽样单元是
一个 HDFS 数据块。因此,如果表的数据大小小于普通的块大小 128M 的话,那么将会返回
所有行。
函数
1 | # 查看所有的函数 |
- 自定义函数
- Hive 本身有一些函数,但是实际应用过程中,这些函数还不够,可能需要自定义一些便于使用。
UDF:User-defined-functions:一进一出
UDAF: user-defined-aggregation-functions聚集函数:多进一出
UDTF:user-defined-table generating -functions:一进多出
如何自定义函数
:
- 创建一个类让这个类继承UDF
- 写一个方法:evaluate
- 将写完的程序打成jar包发送发HIve的lib目录
- 将jar包添加到Hive的CLASSPATH中
1
hive (bigdata)> add jar /opt/apps/Hive/hive-2.3.3/lib/myudf.jar;
创建函数与java 的class进行关联
1
hive (bigdata)> create temporary function myLower as "com.zhiyou100.hadoop.hive.udf.Lower";
应用这个函数
1
hive (bigdata)> select name,mylower(name) from test_udf;
如何自定义UDAF
:
压缩存储
- 开启 Map 输出阶段压缩
- 开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
1 | # 开启 hive 中间传输数据压缩功能 |
- 开启 Reduce 输出阶段压缩
- 当 Hive 将输出写入到表中时,输出内容同样可以进行压缩。属性 hive.exec.compress.output 控制着这个功能。用户可能需要保持默认设置文件中的默认值 false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为 true,来开启输出结果压缩功能。
1 | # 开启 hive 最终输出数据压缩功能 |
- 文件存储格式
- Hive 支持的存储数的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
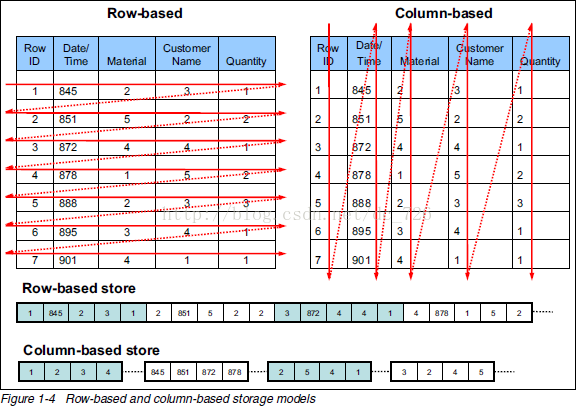
列式存储和行式存储
![image_1cknb37dhsk0m3v1o0hj0kpht1m.png-62.7kB][3]
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
1. TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
2. ORC格式
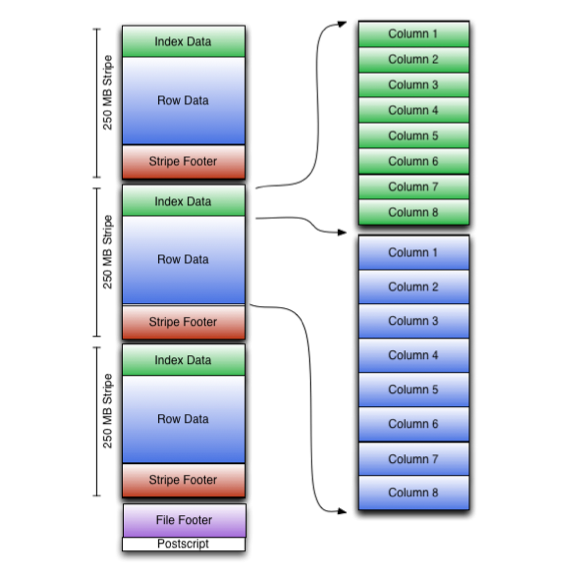
Orc (Optimized Row Columnar)是 hive 0.11 版里引入的新的存储格式。
每个 Orc 文件由 1 个或多个 stripe 组成,每个 stripe250MB 大小,这个 Stripe 实际相当于 RowGroup 概念,不过大小由 4MB->250MB,这样应该能提升顺序读的吞吐率。每个 Stripe 里有三部分组成,分别是 Index Data,Row Data,Stripe Footer:
![image_1ckpt5kq5133k17101v331tfacj919.png-144kB][4]
- Index Data:一个轻量级的 index。这里做的索引应该只是记录某行的各字段在 Row Data 中的 offset。
- Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个 Stream 来存储。
- Stripe Footer:存的是各个 Stream 的类型,长度等信息。每个文件有一个 File Footer,这里面存的是每个 Stripe 的行数,每个 Column 的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter 的长度信息等。在读取文件时,会 seek 到文件尾部读 PostScript,从里面解析到 File Footer 长度,再读 FileFooter,从里面解析到各个 Stripe 信息,再读各个 Stripe,即从后往前读。
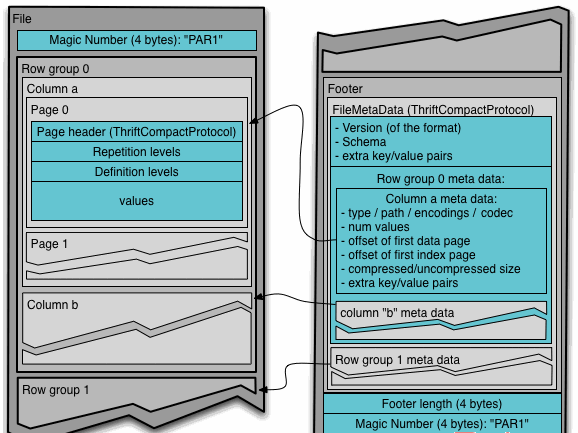
3. PARQUET格式
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目。
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此 Parquet 格式文件是自解析的。
![image_1ckptj64a1qic1h8bcstkdcbgr1m.png-69.3kB][5]存储文件格式压缩比较
:
上传文件到master
创建表:文件格式为TEXTFILE
1
2
3
4
5
6hive (bigdata)> create table log_textfile(time string,url string,session_id string,referer string,ip string,user_id string,city_id string)
> row format delimited fields terminated by '\t'
> stored as textfile;
hive (bigdata)> load data local inpath '/opt/test/log.data' into table log_textfile;
hive (bigdata)> dfs -du -h /hive/warehouse/bigdata.db/log_textfile/log.data;
18.1 M /hive/warehouse/bigdata.db/log_textfile/log.data创建表:文件格式为ORC
1
2
3
4
5
6hive (bigdata)> create table log_orc(time string,url string,session_id string,referer string,ip string,user_id string,city_id string)
> row format delimited fields terminated by '\t'
> stored as orc;
hive (bigdata)> insert into table log_orc select * from log_textfile;
hive (bigdata)> dfs -du -h /hive/warehouse/bigdata.db/log_orc/;
2.8 M /hive/warehouse/bigdata.db/log_orc/000000_0- 创建表:文件格式为PARQUET
1
2
3
4
5
6hive (bigdata)> create table log_parquet(time string,url string,session_id string,referer string,ip string,user_id string,city_id string)
> row format delimited fields terminated by '\t'
> stored as parquet;
hive (bigdata)> insert into table log_parquet select * from log_textfile;
hive (bigdata)> dfs -du -h /hive/warehouse/bigdata.db/log_parquet/;
13.1 M /hive/warehouse/bigdata.db/log_parquet/000000_0
存储文件的压缩比总结:
ORC > Parquet > textFile- 创建表:文件格式为PARQUET
- 文件格式的查询效率
1
2
3
4
5
6
7
8
9## textfile
hive (bigdata)> select count(*) from log_textfile;
Time taken: 28.759 seconds, Fetched: 1 row(s)
## orc
hive (bigdata)> select count(*) from log_orc;
Time taken: 0.122 seconds, Fetched: 1 row(s)
## parquet
hive (bigdata)> select count(*) from log_parquet;
Time taken: 0.113 seconds, Fetched: 1 row(s)
Hive优化
- Fetch 抓取
- Fetch 抓取是指,Hive 中对某些情况的查询可以不必使用 MapReduce 计算。例如:SELECT * FROM student;在这种情况下,Hive 可以简单地读取 student 对应的存储目录下的文件,然后输出查询结果到控制台。
hive.fetch.task.conversion属性的设置
该属性默认为 more 以后,在全局查找、字段查找、limit 查找等都不走MR
- 本地模式
- 大多数的 Hadoop Job 是需要 Hadoop 提供的完整的可扩展性来处理大数据集的。不过,有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务时消耗可能会比实际 job 的执行时间要多的多。对于大多数这种情况,Hive 可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
hive.exec.mode.local.auto属性。让 Hive 在适当的时候自动启动这个优化
1 | # 开启本地模式 |
表的优化
:
小表、大表 Join
将 key 相对分散,并且数据量小的表放在 join 的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用 Group 让小的维度表(1000 条以下的记录条数)先进内存。在 map 端完成 reduce。但是在新版的 hive 已经对小表 JOIN 大表和大表 JOIN 小表进行了优化。小表放在左边和右边已经没有明显区别。大表 Join 大表
空 KEY 过滤
有时 join 超时是因为某些 key 对应的数据太多,而相同 key 对应的数据都会发送到相同的 reducer 上,从而导致内存不够。此时我们应该仔细分析这些异常的 key,很多情况下,这些 key 对应的数据是异常数据,我们需要在 SQL 语句中进行过滤。例如 key 对应的字段为空,1
2
3
4## 过滤空key
select * from table1 t1 left join table2 t2 on t1.id = t2.id;
select * from (select * from table1 where id is not null) n left join table2 t2 on n.id = t2.id;空 key 转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上。1
2
3
4
5
6select * from table1 t1 full join table2 t2 on
case
when t1.id is null
then concat('hahahaha',rand())
else
t1.id = t2.id;
MapJoin
如果不指定 MapJoin 或者不符合 MapJoin 的条件,那么 Hive 解析器会将 Join 操作转换成 Common Join,即:在 Reduce 阶段完成 join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。
hive.auto.convert.join属性设置
大表小表的阀值设置(默认 25M 一下认为是小表)
hive.mapjoin.smalltable.filesizeGroup By
默认情况下,Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时就倾斜了。
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
开启 Map 端聚合参数设置1
2
3
4
5
6# 是否在 Map 端进行聚合,默认为 True
hive.map.aggr = true
# 在 Map 端进行聚合操作的条目数目
hive.groupby.mapaggr.checkinterval = 100000
# 有数据倾斜的时候进行负载均衡(默认是 false),当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
hive.groupby.skewindata = trueCount(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个 Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般 COUNT Distinct 使用先 GROUP BY 再 COUNT 的方式替换:笛卡尔积
尽量避免笛卡尔积,join 的时候不加 on 条件,或者无效的 on 条件,Hive 只能使用 1 个 reducer 来完成笛卡尔积行列过滤
列处理:在 SELECT 中,只拿需要的列,如果有,尽量使用分区过滤,少用 SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在 Where 后面,那么就会先全表关联,之后再过滤,不好。应该先过滤再关联1
2
3
4
5## 这种方式不好
select * from table1 t1 join table2 t2 on t1.id = t2.id where t2.id<100
## 下面的方式较优
select * from table1 t1 join (select id from table2 where id<100) n on t1.id=n.id动态分区调整
关系型数据库中,对分区表 Insert 数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用 Hive 的动态分区,需要进行相应的配置。
开启动态分区参数设置1
2
3
4
5
6
7
8
9
10
11
12# 开启动态分区功能(默认 true,开启)
hive.exec.dynamic.partition=true
# 设置为非严格模式(动态分区的模式,默认 strict,表示必须指定至少一个分区为静态分区,nonstrict 模式表示允许所有的分区字段都可以使用动态分区。)
hive.exec.dynamic.partition.mode=nonstrict
# 在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。
hive.exec.max.dynamic.partitions=1000
# 在每个执行 MR 的节点上,最大可以创建多少个动态分区。该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即 day 字段有 365 个值,那么该参数就需要设置成大于 365,如果使用默认值 100,则会报错。
hive.exec.max.dynamic.partitions.pernode=100
# 整个 MR Job 中,最大可以创建多少个 HDFS 文件。
hive.exec.max.created.files=100000
# 当有空分区生成时,是否抛出异常。一般不需要设置。
hive.error.on.empty.partition=false
数据倾斜
:
合理设置 Map 数
- 通常情况下,作业会通过 input 的目录产生一个或者多个 map 任务。
主要的决定因素有:input 的文件总个数,input 的文件大小,集群设置的文件块大小。 - 是不是 map 数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小 128m),则每个小文件也会被当做一个块,用一个 map 任务来完成,而一个 map 任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的 map 数是受限的。 - 是不是保证每个 map 处理接近 128m 的文件块,就高枕无忧了?
答案也是不一定。比如有一个 127m的文件,正常会用一个 map 去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果 map 处理的逻辑比较复杂,用一个 map 任务去做,肯定也比较耗时。
- 通常情况下,作业会通过 input 的目录产生一个或者多个 map 任务。
小文件进行合并
在 map 执行前合并小文件,减少 map 数:CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat 默认有对小文件合并功能。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;复杂文件增加 Map 数
当 input 的文件都很大,任务逻辑复杂,map 执行非常慢的时候,可以考虑增加 Map 数,来使得每个 map 处理的数据量减少,从而提高任务的执行效率。
增加 map 的方法为:根据 computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M 公式,调整 maxSize 最大值。让 maxSize 最大值低于 blocksize 就可以增加 map 的个数。合理设置 Reduce 数
- 每个 Reduce 处理的数据量默认是 256MB(参数1)
hive.exec.reducers.bytes.per.reducer=256000000 - 每个任务最大的 reduce 数,默认为 1009(参数2)
hive.exec.reducers.max=1009 - 计算 reducer 数的公式
N=min(参数 2,总输入数据量/参数 1)
- 每个 Reduce 处理的数据量默认是 256MB(参数1)
reduce 个数并不是越多越好
- 过多的启动和初始化 reduce 也会消耗时间和资源;
- 另外,有多少个 reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;在设置 reduce 个数的时候也需要考虑这两个原则:处理大数据量利用合适的 reduce 数;使单个 reduce 任务处理数据量大小要合适;
- 并行执行
- Hive 会将一个查询转化成一个或者多个阶段。这样的阶段可以是 MapReduce 阶段、抽样阶段、合并阶段、limit 阶段。或者 Hive 执行过程中可能需要的其他阶段。默认情况下,Hive 一次只会执行一个阶段。不过,某个特定的 job 可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个 job 的执行时间缩短。不过,如果有更多的阶段可以并行执行,那么 job 可能就越快完成。
通过设置参数 hive.exec.parallel 值为 true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果 job 中并行阶段增多,那么集群利用率就会增加。
1
2
3
4# 打开任务并行执行
set hive.exec.parallel=true;
# 同一个 sql 允许最大并行度,默认为 8。
set hive.exec.parallel.thread.number=10;
当然,得是在系统资源比较空闲的时候才有优势,否则,没资源,并行也起不来。
- 严格模式
- Hive 提供了一个严格模式,可以防止用户执行那些可能意想不到的不好的影响的查询。
- JVM 重用
- JVM 重用是 Hadoop 调优参数的内容,其对 Hive 的性能具有非常大的影响,特别是对于很难避免小文件的场景或 task 特别多的场景,这类场景大多数执行时间都很短。
Hadoop 的默认配置通常是使用派生 JVM 来执行 map 和 Reduce 任务的。这时 JVM 的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM 重用可以使得 JVM 实例在同一个 job 中重新使用 N 次。N 的值可以在 Hadoop 的 mapred-site.xml 文件中进行配置。通常在 10-20 之间,具体多少需要根据具体业务场景测试得出。
mapreduce.job.jvm.numtasks
这个功能的缺点是,开启 JVM 重用将一直占用使用到的 task 插槽,以便进行重用,直到任务完成后才能释放。如果某个“不平衡的”job 中有某几个 reduce task 执行的时间要比其他 Reduce task 消耗的时间多的多的话,那么保留的插槽就会一直空闲着却无法被其他的 job 使用,直到所有的 task 都结束了才会释放。
推测执行
:
- 执行计划
- 用于帮助分析SQL语句
- 基本语法
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query- 查看下面这条语句的执行计划
hive (default)> explain select * from student;
- 查看下面这条语句的执行计划
面试题
order by,sort by,distribute by,cluster by的区别
:
- order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间。
- sort by不是全局排序,其在数据进入reducer前完成排序,因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只会保证每个reducer的输出有序,并不保证全局有序。sort by不同于order by,它不受hive.mapred.mode属性的影响,sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定或者reduces),对输出的数据再执行归并排序,即可得到全部结果。
- distribute by 是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
注:Distribute by和sort by的使用场景- Map输出的文件大小不均。
- Reduce输出文件大小不均。
- 小文件过多。
- 文件超大。
- cluster by 除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒叙排序,不能指定排序规则为ASC或者DESC。
行列转换
:
- 行转列
name constellation blood_type 孙悟空 白羊座 A 大海 射手座 A 宋宋 白羊座 B 猪八戒 白羊座 A 凤姐 射手座 A 需求:把星座和血型一样的人归类到一起 1
2
3
4
5
6
7
8
9
10
11
12
13## 将后两列的数据拼接起来,concat('','','',''),比如concat('A','B','C') = ABC
select name,concat(star,"-",blood) sb from person
## concat_ws('A','B','C','D')=BACAD
select
t2.sb,concat_ws(',',collect_set(t2.name))
from
(select
name,concat(star,"-",blood) sb
from
person
) t2
group by
t2.sb;
- 列转行
movie category 《疑犯追踪》 悬疑,动作,科幻,剧情 《Lie to me》 悬疑,警匪,动作,心理,剧情 《战狼 2》 战争,动作,灾难 需求:将电影分类中的数组数据展开 1
2
3
4
5
6
7
8
9
10
11select
t1.t,concat_ws(',',collect_set(t1.name))
from
(
select
t,name
from
movie lateral view explode(type) table_tmp as t
) t1
group by
t1.t;
Hive的Java API操作
- 本机模式
- 简单来说,就是在Hive安装的机器上开启一个客户端,直接使用HQL语句进行Hive命令的操作,不需要指定端口号和IP地址
- 远程模式
- 简单来说,其实就是将装hive的机器看做一个服务器,通过IP和端口号来远程连接Hive,然后操作HQL语句。
1 | <property> |
1 | <property> |
1 | 先启动元数据库,在命令行中键入:hive --service metastore & |
通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作,两者都允许远程客户端使用多种编程语言如Java、Python向Hive提交请求,取回结果。HiveServer或者HiveServer2都是基于Thrift的,但HiveSever有时被称为Thrift server,而HiveServer2却不会。
既然已经存在HiveServer为什么还需要HiveServer2呢?这是因为HiveServer不能处理多于一个客户端的并发请求,这是由于HiveServer使用的Thrift接口所导致的限制,不能通过修改HiveServer的代码修正。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供了更好的支持。