HBase
HBase简介
HBase起源
HBase 的原型是 Google 的 BigTable 论文,受到了该论文思想的启发,目前作为 Hadoop 的子项目来开发维护,用于支持结构化的数据存储。
- 2006 年 Google 发表 BigTable 白皮书
- 2006 年开始开发 HBase
- 2008 年北京成功开奥运会,程序员默默地将 HBase 弄成了 Hadoop 的子项目
- 2010 年 HBase 成为 Apache 顶级项目
- 现在很多公司二次开发出了很多发行版本。
什么是HBase
HBase(Hadoop DataBase)是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为其分布式协调服务。
用来存储非结构化和半结构化的松散数据。
与传统数据库的对比
- 传统数据库遇到的问题
- 数据量很大的时候无法存储
- 没有很好的备份机制
- 数据达到一定数量开始缓慢,很大的话基本无法支撑
- HBase优势
- 线性扩展,随着数据量增多可以通过节点扩展进行支撑
- 数据存储在hdfs上,备份机制健全
- 通过zookeeper协调查找数据,访问速度块。
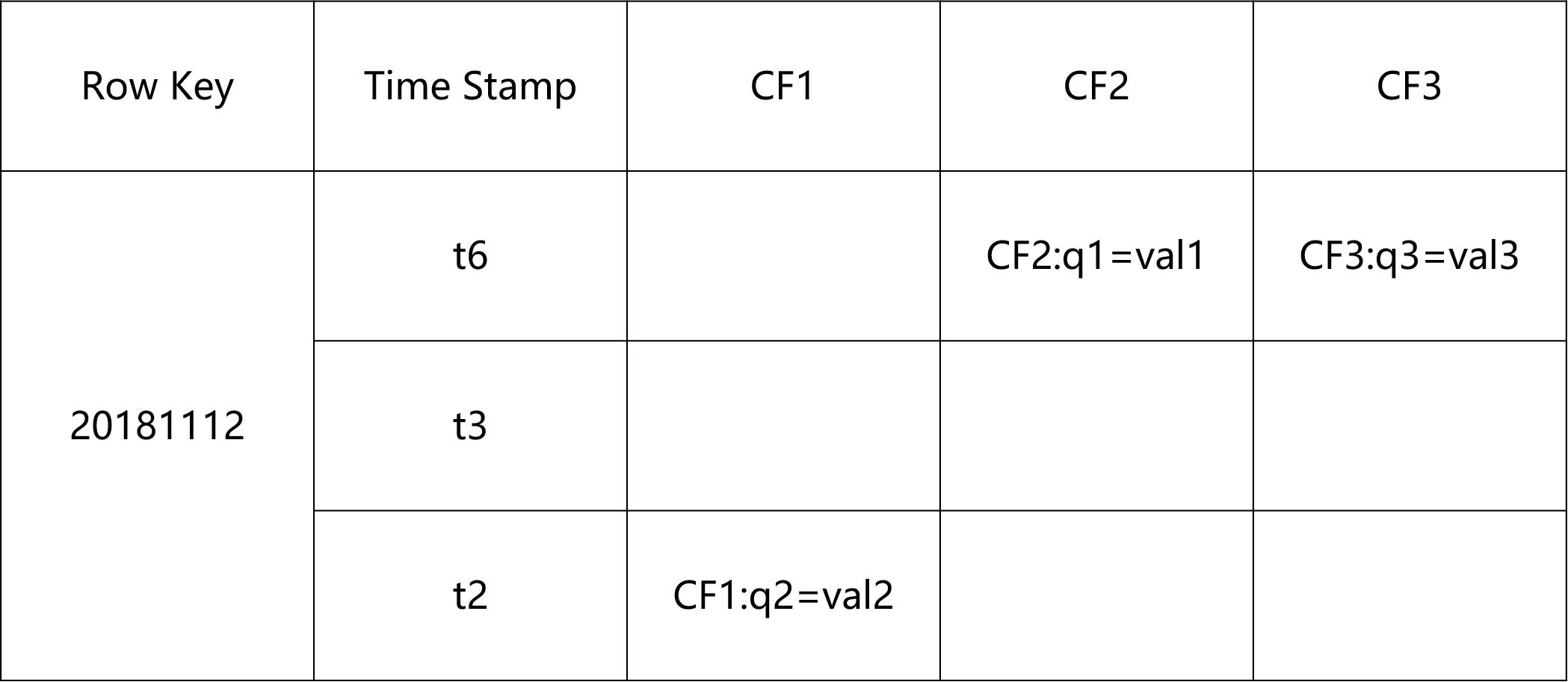
HBase的数据模型
![image_1cs4fmo7c9ncq77hvn14nt1c7f8c.png-61.7kB][1]
ROW KEY
:
- 决定一行数据
- 按照字典顺序排序的。
- Row key只能存储64k的字节数据
Timestamp时间戳
:
- 在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
- 时间戳的类型是 64位整型。
- 时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
- 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
Column Family列族 & qualifier列
:
- HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema)定义的一部分预先给出。如 create ‘test’, ‘info’;
- 列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如info:name, info:age,
- 新的列族成员(列)可以随后按需、动态加入
- 权限控制、存储以及调优都是在列族层面进行
- HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
Cell单元格
:
- 由行和列的坐标交叉决定
- 单元格是有版本的
- 单元格的内容是未解析的字节数组
- 由{row key, column( =
+ ), version} 唯一确定的单元 - cell中的数据是没有类型的,全部是字节码形式存贮。
HLog(WAL log)
:
- HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
- HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
HBase集群中的角色(进程)
- 一个或者多个主节点,Hmaster
- 监控 RegionServer
- 处理 RegionServer 故障转移
- 处理元数据的变更
- 处理 region 的分配或移除
- 在空闲时间进行数据的负载均衡
- 通过 Zookeeper 发布自己的位置给客户端
- 多个从节点,HregionServer
- 负责存储 HBase 的实际数据
- 处理分配给它的 Region
- 刷新缓存到 HDFS
- 维护 HLog
- 执行压缩
- 负责处理 Region 分片
基本原理
HBase 一种是作为存储的分布式文件系统,另一种是作为数据处理模型的 MR 框架。因为日常开发人员比较熟练的是结构化的数据进行处理,但是在 HDFS 直接存储的文件往往不具有结构化,所以催生出了 HBase 在 HDFS 上的操作。如果需要查询数据,只需要通过键值便可以成功访问。
HBase 内置有 Zookeeper,但一般我们会有其他的 Zookeeper 集群来监管 master 和 regionserver,Zookeeper 通过选举,保证任何时候,集群中只有一个活跃的 HMaster,HMaster 与 HRegionServer 启动时会向 ZooKeeper 注册,存储所有 HRegion 的寻址入口,实时监控 HRegionserver 的上线和下线信息。并实时通知给 HMaster,存储 HBase 的 schema 和 table 元数据,默认情况下,HBase 管理 ZooKeeper 实例,Zookeeper 的引入使得 HMaster 不再是单点故障。一般情况下会启动两个 HMaster,非 Active 的 HMaster 会定期的和 Active HMaster 通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个 HMaster 反而增加了 Active HMaster 的负担。
一个 RegionServer 可以包含多个 HRegion,每个 RegionServer 维护一个 HLog,和多个 HFiles以及其对应的 MemStore。RegionServer 运行于 DataNode 上,数量可以与 DatNode 数量一致,
![image_1clfil80u13cl2tkpib1fuv1jj39.png-336.1kB][2]
组件说明
:
- Write-Ahead logs
HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在写入一个叫做 Write-Ahead logfile的文件中,再写到内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。- HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。 - Store
HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。 - MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在 WAL 中之后,RegsionServer 会在内存中存储键值对。 - Region
Hbase 表的分片,HBase 表会根据 RowKey 值被切分成不同的 region 存储在 RegionServer 中,在一个 RegionServer 中可以有多个不同的 region。
- HFile
HBase 安装部署
- 下载地址
- [点击下载][3]
- 解压
1
[root@master HBase]# tar -zxvf hbase-1.4.6-bin.tar.gz
- 修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37[root@master conf]# vim hbase-env.sh
#添加以下内容
export JAVA_HOME=/opt/apps/Java/jdk1.8.0_172
export HBASE_HOME=/opt/apps/HBase/hbase-1.4.6
export HBASE_CLASSPATH=$CLASSPATH:$HBASE_HOME/lib
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
[root@master conf]# vim hbase-site.xml
# 添加以下内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181,slave3:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/apps/Zookeeper/data</value>
</property>
</configuration>
[root@master conf]# vim regionservers
# 添加以下内容
slave1
slave2
slave3
master
- 解决Jar包问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[root@master lib]# rm -rf hadoop-*
[root@master lib]# rm -rf zookeeper-3.4.10.jar
[root@master lib]# cp ./* /opt/apps/HBase/hbase-1.4.6/lib/
hadoop-annotations-2.7.6.jar
hadoop-auth-2.7.6.jar
hadoop-client-2.7.6.jar
hadoop-common-2.7.6.jar
hadoop-hdfs-2.7.6.jar
hadoop-mapreduce-client-app-2.7.6.jar
hadoop-mapreduce-client-common-2.7.6.jar
hadoop-mapreduce-client-core-2.7.6.jar
hadoop-mapreduce-client-jobclient-2.7.6.jar
hadoop-mapreduce-client-shuffle-2.7.6.jar
hadoop-yarn-api-2.7.6.jar
hadoop-yarn-client-2.7.6.jar
hadoop-yarn-common-2.7.6.jar
hadoop-yarn-server-common-2.7.6.jar
zookeeper-3.4.12.jar
- 在HBase中添加Hadoop的配置文件
1
2
3# 通过软连接的方式创建
[root@master conf]# ln -s /opt/apps/Hadoop/hadoop-2.7.6/etc/hadoop/core-site.xml /opt/apps/HBase/hbase-1.4.6/conf/core-site.xml
[root@master conf]# ln -s /opt/apps/Hadoop/hadoop-2.7.6/etc/hadoop/hdfs-site.xml /opt/apps/HBase/hbase-1.4.6/conf/hdfs-site.xml
分发
:
- 访问WEB UI
- http://master:16010/
HBase 的 Shell 操作
命令操作
:
1 | # 进入到HBase的Shell |
HBase 的 API 操作
HBASE的读写流程
画图
读数据流程
:
- region server 保存着meta表以及数据,要想访问数据,客户端必须先通过Zookeeper获取-ROOT-的位置信息
- 通过-ROOT-来获取meta中的region的位置,
- 客户端通过meta获取数据的region位置
- 通过region的位置获取数据
写数据的流程
:
- 客户端先访问zookeeper,找到元数据信息
- 确定要写入的数据是在哪一个region上
- 然后客户端向该region server发送写数据的请求
- 客户端先把数据写入到Hlog中,以及所需要的操作,防止数据的丢失
- 然后写入Memstore
- 如果Hlog和Memstore均写入成功,则表示该数据写入成功。如果在这个过程中,Memstore的数据达到了阈值,就会将Memstore中的数据刷新到storefile
- storefile过多的时候,region就会越来越大,如果达到阈值,那么region会被master一分为2
- storefile最后会不断的溢出成Hfile
- 在region server空闲的时候,会将HFile这些小文件进行合并
HBase 的 MR
通过 HBase 的相关 JavaAPI,我们可以实现伴随 HBase 操作的 MapReduce 过程,比如使用 MapReduce 将数据从本地文件系统导入到 HBase 的表中,比如我们从 HBase 中读取一些原始数据后使用 MapReduce 做数据分析。
官方HBase MR的应用
- 统计Hbase表中的行数
1
2
3
4
5
6# 统计Hbase表中的行数
[root@master lib]# yarn jar hbase-server-1.4.6.jar rowcounter student
# 报错
# Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/hase/filter/Filter
# 解决方案
# 在环境变量中添加HADOOP_CLASSPATH变量,将HBase的jar包添加进去
- 导入HDFS上的文件到HBase
1
2
3
4
5
6
7
8
9
10
11
12
13[root@master lib]# vim input_hbase.tsv
## 添加数据
11111 zhangsan 18
11112 lisi 17
11113 wangwu 99
11114 zhaoliu 100
## 上传至Hadoop
[root@master lib]# hadoop fs -mkdir /hbase/mr/
[root@master lib]# hadoop fs -put input_hbase.tsv /hbase/mr/
## 在HBase上创建相应的表,否则会出现表不存在的异常
hbase(main):001:0> create 'people','info'
## 执行
[root@master lib]# yarn jar hbase-server-1.4.6.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age people hdfs://master:9000/hbase/mr
自定义HBase MR
扩充-hbase过滤器
- FilterList
- FilterList 代表一个过滤器列表,可以添加多个过滤器进行查询,多个过滤器之间的关系有:
与关系(符合所有):FilterList.Operator.MUST_PASS_ALL
或关系(符合任一):FilterList.Operator.MUST_PASS_ONE
- 使用方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ONE);
Scan s1 = new Scan();
filterList.addFilter(new SingleColumnValueFilter(
Bytes.toBytes(“f1”),
Bytes.toBytes(“c1”),
CompareOp.EQUAL,Bytes.toBytes(“v1”)));
filterList.addFilter(new SingleColumnValueFilter(
Bytes.toBytes(“f1”),
Bytes.toBytes(“c2”),
CompareOp.EQUAL,Bytes.toBytes(“v2”)));
// 添加下面这一行后,则只返回指定的cell,同一行中的其他cell不返回
s1.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(“c1”));
s1.setFilter(filterList); //设置filter
ResultScanner ResultScannerFilterList = table.getScanner(s1);//返回结果列表
过滤器的种类
:
- 列值过滤器—SingleColumnValueFilter
过滤列值的相等、不等、范围等 - 列名前缀过滤器—ColumnPrefixFilter
过滤指定前缀的列名 - 多个列名前缀过滤器—MultipleColumnPrefixFilter
过滤多个指定前缀的列名 - rowKey过滤器—RowFilter
通过正则,过滤rowKey值。
- 列值过滤器—SingleColumnValueFilter
- SingleColumnValueFilter 列值判断
相等 (CompareOp.EQUAL ),
不等(CompareOp.NOT_EQUAL),
范围 (e.g., CompareOp.GREATER)…………
下面示例检查列值和字符串’values’ 相等…
1
2
3
4
5
6SingleColumnValueFilter f = new SingleColumnValueFilter(
Bytes.toBytes("cFamily"),
Bytes.toBytes("column"),
CompareFilter.CompareOp.EQUAL,
Bytes.toBytes("values"));
s1.setFilter(f);
注意:如果过滤器过滤的列在数据表中有的行中不存在,那么这个过滤器对此行无法过滤。
- 列名前缀过滤器—ColumnPrefixFilter
- 过滤器—ColumnPrefixFilter
ColumnPrefixFilter 用于指定列名前缀值相等
1
2ColumnPrefixFilter f = new ColumnPrefixFilter(Bytes.toBytes("values"));
s1.setFilter(f);
- 多个列值前缀过滤器—MultipleColumnPrefixFilter
- MultipleColumnPrefixFilter 和 ColumnPrefixFilter 行为差不多,但可以指定多个前缀
1
2
3byte[][] prefixes = new byte[][] {Bytes.toBytes("value1"),Bytes.toBytes("value2")};
Filter f = new MultipleColumnPrefixFilter(prefixes);
s1.setFilter(f);
- rowKey过滤器—RowFilter
- RowFilter 是rowkey过滤器
通常根据rowkey来指定范围时,使用scan扫描器的StartRow和StopRow方法比较好。
1
2
3
4Filter f = new RowFilter(
CompareFilter.CompareOp.EQUAL,
new RegexStringComparator("^1234")); //匹配以1234开头的rowkey
s1.setFilter(f);
HBase与Hive的区别
Hive
:
- 数据仓库
Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个映射关系,以方便使用 HQL 去管理查询。 - 用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。 - 基于 HDFS 、MapReduce
Hive 存储的数据依旧在 DataNode 上,编写的 HQL 语句终将是转换为 MapReduce 代码执行。
HBase
:
- 数据库
是一种面向列存储的分布式的非关系型数据库。 - 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN 等操作。 - 基于 HDFS
数据持久化存储的体现形式是 Hfile,存放于 DataNode 中,被 ResionServer 以 region 的形式进行管理。 - 延迟较低,适合接入在线业务使用
面对大量的企业数据,HBase 可以实现单表大量数据的存储,同时提供了高效的数据访问速度。
Hive与HBase的集成操作
配置
:
- 替换相应JAR包
- 修改配置文件
1
- 简单操作1
- 在Hive中导入数据的时候,直接关联HBase表,插入到Hive中的数据可以直接同步到HBase中。
1 | hive (default)> create table hive_hbase_people(id int,name string,age int) |
- 简单操作2
- 假设HBase中的某一个表中,已经存储了一些数据,现在需要使用Hive的外部表来关联HBase的这个表,可以借助Hive进行离线数据分析。
1 | # 在HBase 创建相应的表 |
sqoop与HBase的集成操作
- 配置
1
2
3
4
5
6[root@master ~]# vim /opt/apps/Sqoop/sqoop-1.4.7/conf/sqoop-env.sh
set the path to where bin/hbase is available
export HBASE_HOME=/opt/apps/HBase/hbase-1.4.6
Set the path for where zookeper config dir is
export ZOOKEEPER_HOME=/opt/apps/Zookeeper/zookeeper-3.4.12
export ZOOCFGDIR=$ZOOKEEPER_HOME/conf
相关参数
| 参数 | 描述 |
|---|---|
| –column-family |
Sets the target column family for the import设置导入的目标列族。 |
| –hbase-create-table | If specified, create missing HBase tables 是否自动创建不存在的 HBase 表(这就意味着,不需要手动提前在 HBase 中先建立表) |
| –hbase-row-key |
Specifies which input column to use as the row key.In case, if input table contains composite key, then |
| –hbase-table |
Specifies an HBase table to use as the target instead of HDFS.指定数据将要导入到 HBase 中的哪张表中。 |
| –hbase-bulkload | Enables bulk loading.是否允许 bulk 形式的导入。 |
- 简单使用
1
2
3
4
5
6
7
8
9
10[root@master ~]# sqoop import \
--connect jdbc:mysql://master:3306/mysql_bigdata \
--username root \
--password 123456 \
--table product \
--columns "id,name,price" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_sqoop_product_1" \
--column-family "info"
Hbase shell的其他命令
数据的备份与恢复
- 备份
- 停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群。
即,把数据转移到当前集群的其他目录下(也可以不在同一个集群中)
- 恢复
- 非常简单,与备份方法一样,将数据整个移动回来即可。
节点的管理
- 服役(commissioning )
- 当启动 regionserver 时,regionserver 会向 HMaster 注册并开始接收本地数据,开始的时候,新加入的节点不会有任何数据,平衡器开启的情况下,将会有新的 region 移动到开启的RegionServer 上。如果启动和停止进程是使用 ssh 和 HBase 脚本,那么会将新添加的节点的主机名加入到 conf/regionservers 文件中。
退役(decommissioning)
: 顾名思义,就是从当前 HBase 集群中删除某个 RegionServer
- 停止负载均衡器
- 停止region server
Hbase 的优化
高可用
: 在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以 HBase 支持对 Hmaster 的高可用配置。
1 | [root@master conf]# vim backup-masters |
Hadoop 高可用
:
1
2
3
4
5
6
7
8
9
10
11
# 配置多个namenode
#core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hacluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181,slave3:2181,slave4:2181</value>
</property>
# hdfs-site.xml
- Linux优化
1
2
3
4
5
6
7
8
9
10
11
12# 1. 开启文件预读缓存:ra:readahead
blockdev --setra 1024 /dev/sda
# 2. 关闭进程睡眠池:不允许后台进程进入睡眠状态,如果这个进程是空闲的,那么直接kill掉
sysctl -w vm.swappiness=0
# 调整允许打开最大的文件数和线程数
ulimit -u ## 允许打开最大文件数
ulimit -n ## 查看允许最大的进程数
#可以在下面的文件中修改
/etc/security/limits.conf
# 3. 补丁更新
- zookeeper优化
- session.timeout设置为30秒
HBase优化
预分区
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。rowkey的设计
该数据被分到哪一个region中看的是rowkey。HBase中row key用来检索表中的记录,支持以下三种方式:
- 通过单个row key访问:即按照某个row key键值进行get操作
- 通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
- 全表扫描:即直接扫描整张表中所有行记录。
在HBase中,row key可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组,一般设计成定长的。row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为row key的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE - timestamp作为row key,这样能保证新写入的数据在读取时可以被快速命中。
- 生成随机数,hash,散列值
1001,sha1:dd01903921ea24941c26a48f2cec24e0bb0e8cc7 1002,sha1:a5b1d7e217aa227d5b2b8a84920780cf637960e2 - 字符串反转
201808231000000001反转后100000000132808102 - 字符串拼接
原来的字符串拼接一个随机字符串 - rowkey长度原则
不要太长,限定在100个字节以内 - rowkey唯一原则
列族
不要在一张表里定义太多的column family。目前Hbase并不能很好的处理超过2~3个column family的表。因为某个column family在flush的时候,它邻近的column family也会因关联效应被触发flush,最终导致系统产生更多的I/O。[点击这里有说明][4]
In Memory
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到RegionServer的缓存中,保证在读取的时候被cache命中。
Max Version
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)。
Time To Live
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
Hbase和DBMS比较:
查询数据不灵活:
- 不能使用column之间过滤查询
- 不支持全文索引。使用solr和hbase整合完成全文搜索。
- 使用MR批量读取hbase中的数据,在solr里面建立索引(no store)之保存rowkey的值。
- 根据关键词从索引中搜索到rowkey(分页)
- 根据rowkey从hbase查询所有数据