Hadoop-HDFS
1. HDFS的概念和特性
- 首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
- 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下
:
- HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在Hadoop2.x版本中是128M,Hadoop1.x版本中是64M
- HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://master:port/dir-a/dir-b/dir-c/file.data,http://master:50070
- 目录结构及文件分块信息(元数据)的管理由master节点承担
namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的slave服务器文件的- 各个block的存储管理由datanode节点承担。datanode是HDFS集群从节点(数据节点),每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
- HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
优点
:
- 高容错性
数据自动保存多个副本。它通过增加副本的形式,提高容错性。
某一个副本丢失以后,它可以自动恢复。- 适合大数据处理
数据规模:能够处理数据规模达到 GB、TB、甚至 PB 级别的数据。
文件规模:能够处理百万规模以上的文件数量,数量相当之大。 - 流式数据访问
一次写入,多次读取,不能修改,只能追加。
它能保证数据的一致性。 - 可构建在廉价机器上,通过多副本机制,提高可靠性。
- 适合大数据处理
缺点
:
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
- 无法高效的对大量小文件进行存储
存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件、目录和块信息。这样是不可取的,因为 NameNode 的内存总是有限的。
小文件存储的寻址时间会超过读取时间,它违反了 HDFS 的设计目标。- 并发写入、文件随机修改
一个文件只能有一个写,不允许多个线程同时写。
仅支持数据 append(追加),不支持文件的随机修改。
- 并发写入、文件随机修改
2. HDFS
- 设计思想
- 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析
- 在大数据系统中作用
- 为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务
- 重点概念
- 文件切块,副本存放,元数据
3. HDFS的shell(命令行客户端)操作
3.1 HDFS命令行客户端使用
HDFS提供shell命令行客户端,使用方法如下:
1 | [root@master ~]# hadoop fs -ls / |
3.2 常用命令参数介绍
- -help
- 功能:输出这个命令参数手册
- -ls
- 功能:显示目录信息
示例: hadoop fs -ls hdfs://master:9000/
备注:这些参数中,所有的hdfs路径都可以简写
–>hadoop fs -ls / 等同于上一条命令的效果
- -mkdir
- 功能:在hdfs上创建目录
示例:hadoop fs -mkdir -p /a/b/c/d
- -moveFromLocal
- 功能:从本地剪切粘贴到hdfs
示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
- -moveToLocal
- 功能:从hdfs剪切粘贴到本地
示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
- -appendToFile
- 功能:追加一个文件到已经存在的文件末尾
示例:hadoop fs -appendToFile ./hello.txt hdfs://master:9000/hello.txt
可以简写为:
Hadoop fs -appendToFile ./hello.txt /hello.txt
- -cat
- 功能:显示文件内容
示例:hadoop fs -cat /hello.txt
- -tail
- 功能:显示一个文件的末尾
示例:hadoop fs -tail /hello.txt
- -text
- 功能:以字符形式打印一个文件的内容
示例:hadoop fs -text /hello.txt
- -chmod
- 功能:linux文件系统中的用法一样,对文件所属权限
示例:
hadoop fs -chmod 666 /hello.txt
- -copyFromLocal
- 功能:从本地文件系统中拷贝文件到hdfs路径去
示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
- -copyToLocal
- 功能:从hdfs拷贝到本地
示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz
- -cp
- 功能:从hdfs的一个路径拷贝hdfs的另一个路径
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
- -mv
- 功能:在hdfs目录中移动文件
示例: hadoop fs -mv /aaa/jdk.tar.gz /
- -get
- 功能:等同于copyToLocal,就是从hdfs下载文件到本地
示例:hadoop fs -get /aaa/jdk.tar.gz
- -getmerge
- 功能:合并下载多个文件
示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum
- -put
- 功能:等同于copyFromLocal
示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
- -rm
- 功能:删除文件或文件夹
示例:hadoop fs -rm -r /aaa/bbb/
- -rmdir
- 功能:删除空目录
示例:hadoop fs -rmdir /aaa/bbb/ccc
- -df
- 功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h /
- -du
- 功能:统计文件夹的大小信息
示例:
hadoop fs -du -s -h /aaa/*
- -count
- 功能:统计一个指定目录下的文件节点数量
示例:hadoop fs -count /aaa/
- -setrep
- 功能:设置hdfs中文件的副本数量
示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz
3.3 HDFS 的Java 客户端的操作
:
在windows上创建HADOOP_HOME环境变量
- 修改bin目录的文件
- 复制hadoop.dll文件到c:\windows\system32目录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243package com.zhiyou100.hadoop.hdfs;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.io.IOUtils;
import org.junit.Before;
import org.junit.Test;
/**
* 配置文件的生效顺序(优先级)
* set("","")>src>hadoop-hdfs-2.7.6.jar
* @author zhang
*
*/
public class HDFS_Operate {
FileSystem fs = null;
Configuration conf = null;
public void init() throws Exception{
//获取配置对象
conf = new Configuration();
conf.set("dfs.replication", "2");
//获取文件系统对象
fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "root");
}
/**
* 上传文件
* @throws Exception
*/
public void upload() throws Exception {
fs.copyFromLocalFile(new Path("F:\\work\\hadoop-2.7.6.tar.gz"), new Path("/"));
fs.close();
}
/**
* 下载文件
* @throws Exception
*/
public void download() throws Exception {
/*
* boolean delSrc:是否删除源文件
* Path src:要下载的文件的原路径
* Path dst:文件下载下来要存放的路径
* boolean useRawLocalFileSystem:是否允许使用本地文件系统创建crc文件来进行文件的校验
*/
fs.copyToLocalFile(false, new Path("/aaaaaa.txt"), new Path("G:/"), true);
fs.close();
}
/**
* 用来创建目录
* @throws Exception
* @throws IllegalArgumentException
*/
public void createDir() throws Exception {
fs.mkdirs(new Path("/zhangsan/lisi1"));
fs.close();
}
/**
* 用来删除目录
* true:无论是否为空,均要删除
* false:如果目录不为空,则报错
* @throws Exception
*/
public void deleteDir() throws Exception {
fs.delete(new Path("/zhangsan/lisi1"), true);
fs.close();
}
/**
* 重命名
* @throws Exception
*/
public void rename() throws Exception {
fs.rename(new Path("/aaa.txt"), new Path("/bbb.txt"));
fs.close();
}
/**
* 遍历一个目录下的所有文件
* @throws Exception
*/
public void listFileInfo() throws Exception {
FileStatus[] statuses = fs.listStatus(new Path("/"));
for(FileStatus status:statuses) {
//获取文件名
System.out.println(status.getPath().getName());
//获取文件的长度
System.out.println(status.getLen());
//获取权限
System.out.println(status.getPermission());
//获取块的大小
System.out.println(status.getBlockSize());
}
}
public void listFileBlock() throws Exception{
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);
//判断是否有下一个文件
while(files.hasNext()) {
//LocatedFileStatus继承了上述的FileStatus
//获取的是所有的文件及子目录中的文件
LocatedFileStatus status = files.next();
System.out.println(status.getPath().getName());
//获取存储的Block信息
BlockLocation[] bs = status.getBlockLocations();
for(BlockLocation b:bs) {
System.out.println("下面是该块所属的Block主机");
//得到这个Block所属的datanode节点的Host
String[] hosts = b.getHosts();
for(String host:hosts) {
System.out.println(host);
}
}
System.out.println("-------------");
}
fs.close();
}
/**
* 判断该文件是文件还是文件夹
* @throws Exception
*/
public void getFileType() throws Exception {
//
FileStatus[] files = fs.listStatus(new Path("/"));
for(FileStatus file : files) {
//判断是否为文件
if(file.isFile()) {
System.out.println("文件:"+file.getPath());
}else {
System.out.println("文件夹:"+file.getPath());
}
}
fs.close();
}
/**
* 通过普通的IO操作HDFS
* 文件上传
* @throws Exception
*/
public void putFileToHDFS() throws Exception {
//创建输入流
FileInputStream is = new FileInputStream("D:\\aaaaaa.txt");
//创建输出流
FSDataOutputStream fos = fs.create(new Path("/王果.txt"));
//流拷贝
IOUtils.copyBytes(is, fos, conf);
//关闭流
IOUtils.closeStream(is);
IOUtils.closeStream(fos);
}
/**
* 文件下载
* @throws Exception
*/
public void getFileFromHDFS() throws Exception {
//创建输入流
FSDataInputStream fis = fs.open(new Path("/王果.txt"));
//创建输出流
FileOutputStream fos = new FileOutputStream("F:/王果.txt");
//流拷贝
IOUtils.copyBytes(fis, fos, conf);
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
/**
* 文件下载——分块下载
* @throws Exception
*/
public void getBlockFile() throws Exception {
//获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.6.tar.gz"));
//创建一个输出流
FileOutputStream os = new FileOutputStream("F:/hadoop-2.7.6.tar.gz.part1");
//流拷贝
byte[] buffer = new byte[1024];
for(int i = 0;i<1024*128;i++) {
fis.read(buffer);
os.write(buffer);
}
os.flush();
os.close();
fis.close();
}
/**
* 文件下载——分块下载——第2块
* @throws Exception
*/
public void getBlockFile2() throws Exception {
//获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.6.tar.gz"));
//设置输入流读取的数据位置
fis.seek(1024*1024*128);
//创建一个输出流
FileOutputStream os = new FileOutputStream("F:/hadoop-2.7.6.tar.gz.part2");
//流拷贝
IOUtils.copyBytes(fis, os, conf);
//关闭流
IOUtils.closeStream(fis);
IOUtils.closeStream(os);
}
}
4. hdfs的工作机制
4.1 概述
:
- HDFS集群分为两大角色:NameNode进程、DataNode进程(secondary namenode)
- NameNode 负责管理整个文件系统的元数据
- DataNode 负责管理用户的文件数据块
- 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
- 每一个文件块可以有多个副本,并存放在不同的datanode上
- Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
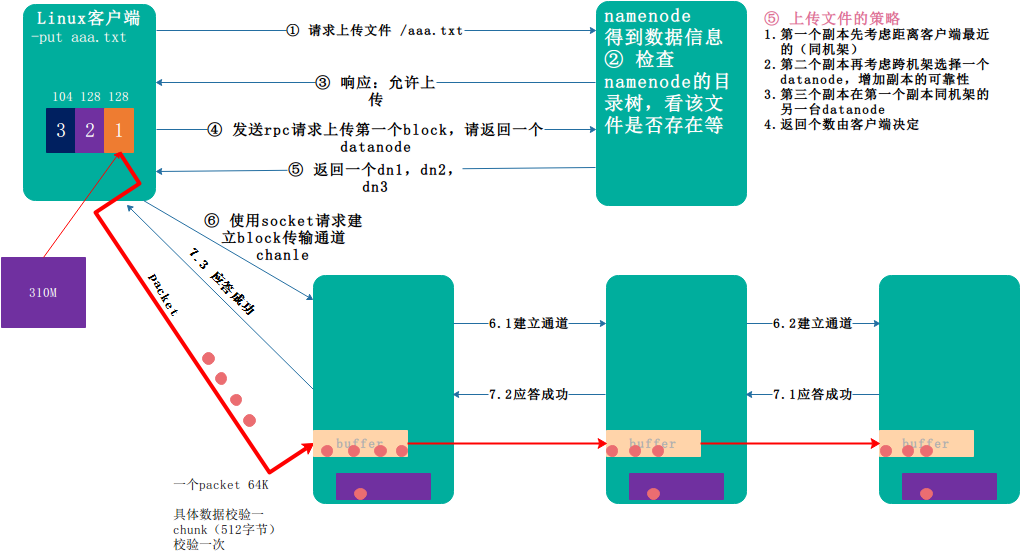
- 4.2 HDFS写数据流程
- 客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本
![image_1cjj6r8ng19kaqu91ekteot11ud9.png-153.9kB][1]
详细步骤解析
- 根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
- namenode返回是否可以上传
- client请求第一个 block该传输到哪些datanode服务器上
- namenode返回3个datanode服务器ABC
- client请求3台dn中的一台A上传数据(建立pipeline),A收到请求会继续调用B,然后B调用C,将一个pipeline建立完成,逐级返回客户端
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
4.2 网络拓扑
:
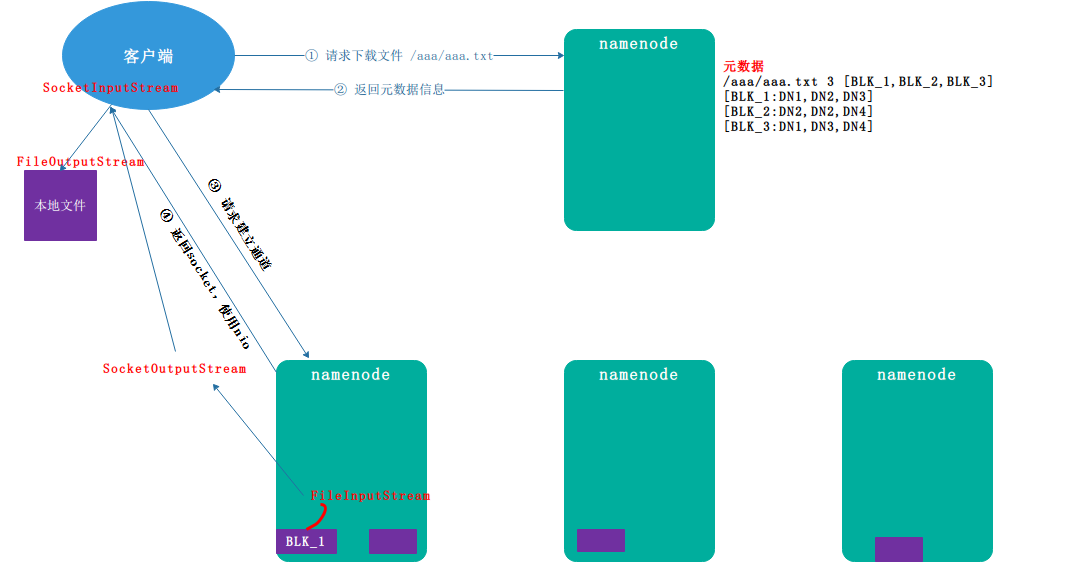
- 4.3. HDFS读数据流程
- 客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
![image_1cjj8j28fiav1vaar38146dov8m.png-73.6kB][2]
详细步骤解析
- 客户端通过 Distributed FileSystem 向 namenode 请求下载文件, 跟 namenode 通信查询元数据,找到文件块所在的datanode服务器
- 挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
- datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件
- 4.3 一致性模型
- 案例
1
2
3
4
5
6
7
8
9
10
11public void put() throws IOException {
//创建一个输出流
FSDataOutputStream fos = fs.create(new Path("/王晨3.txt"));
//写入数据
fos.write("你好,王晨".getBytes());
//一致性刷新
fos.hflush();
fos.close();
fs.close();
}
5. Namenode工作机制
5.1 镜像文件与编辑日志
:
概念
namenode 被格式化之后,将在/opt/apps/Hadoop/hadoop-2.7.6/hdfs/name/current 目录中产生如下文件
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION- Fsimage 文件:HDFS 文件系统元数据的一个永久性的检查点,其中包含 HDFS 文件系统的所有目录和文件 idnode 的序列化信息。 - Edits 文件:存放 HDFS 文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到 edits 文件中。 - seen_txid 文件保存的是一个数字,就是最后一个 edits_的数字 - 每次 Namenode 启动的时候都会将 fsimage 文件读入内存,并从 00001 开始到 seen_txid 中记录的数字依次执行每个 edits 里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成 Namenode 启动的时候就将 fsimage 和 edits 文件进行了合并。oiv 查看 fsimage 文件
- 查看 oiv 和 oev 命令 - 基本语法- 案例1
hdfs oiv -p 返回的文件类型 -i 镜像文件 -o 转换后文件输出的路径
1
[root@master current]# hdfs oiv -p XML -i fsimage_0000000000000000187 -o /opt/data/fsimage.xml
oev 查看 edits 文件
- 基本语法- 案例1
hdfs oev -p 返回的文件类型 -i 编辑日志 -o 转换后文件输出的路径
1
[root@master current]# hdfs oev -p xml -i edits_0000000000000000003-0000000000000000016 -o /opt/data/edit.xml
5.2 Namenode和SecondaryNamenode原理
:
- namenode 启动
- namenode 格式化后,创建 fsimage 文件。
- 如果是第一次启动,那么就会加载镜像文件到内存中
- 如果不是第一次启动,直接加载编辑日志和镜像文件到内存,同时还要做合并操作。
- 客户端对元数据进行增删改的请求。
- namenode 记录操作日志,更新滚动日志。
- namenode 在内存中对数据进行增删改查。
- Secondary NameNode 工作
- Secondary NameNode 询问 namenode 是否需要 checkpoint。直接带回 namenode 是否检查结果。
- Secondary NameNode 请求执行 checkpoint。
- namenode 滚动正在写的 edits 日志。
- 将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
- Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件 fsimage.chkpoint。
- 拷贝 fsimage.chkpoint 到 namenode。
- namenode 将 fsimage.chkpoint 重新命名成 fsimage。
- 原理图
- 5.3 滚动编辑日志
- 正常情况 HDFS 文件系统有更新操作时,就会滚动编辑日志。也可以用命令强制滚动编辑日志。
- 滚动编辑日志(前提必须启动集群)
1
hdfs dfsadmin -rollEdits
- 镜像文件什么时候产生
Namenode 启动时加载镜像文件和编辑日志5.4 Namenode 版本号
:
- 查看 namenode 版本号
在/opt/apps/Hadoop/hadoop-2.7.6/hdfs/name/current 这个目录下查看 VERSION
namespaceID=1483942760
clusterID=CID-da97158f-34cc-4f8f-ad08-421c5fa542f7
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1314907513-192.168.100.100-1532659630649
layoutVersion=-63- namenode 版本号具体解释
- namespaceID 在 HDFS 上,会有多个 Namenode,所以不同 Namenode 的namespaceID 是不同的,分别管理一组 blockpoolID。
- clusterID 集群 id,全局唯一
- cTime 属性标记了 namenode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0;但是在文件系统升级之后,该值会更新到新的时间戳。
- storageType 属性说明该存储目录包含的是 namenode 的数据结构。
- blockpoolID:一个 block pool id 标识一个 block pool,并且是跨集群的全局唯一。当一个新的 Namespace 被创建的时候(format 过程的一部分)会创建并持久化一个唯一 ID。在创建过程构建全局唯一的 BlockPoolID 比人为的配置更可靠一些。NN 将 BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次 load 并使用。
- layoutVersion 是一个负整数。通常只有 HDFS 增加新特性时才会更新这个版本号。
- namenode 版本号具体解释
5.5 web 端访问 SecondaryNameNode 端口号
:
- 启动集群。
- 浏览器中输入:http://master:50090/status.html
- 查看 SecondaryNameNode 信息。
5.6 chkpoint 检查时间参数设置
:
通常情况下,SecondaryNameNode 每隔一小时执行一次。
1
2
3
4
5
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode 执行一次。
1
2
3
4
5
6
7
8
9
10<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1 分钟检查一次操作次数</description>
</property>
5.7 SecondaryNameNode 目录结构
: Secondary NameNode 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS元数据的快照。在 /opt/apps/Hadoop/hadoop-2.7.6/tmp/dfs/namesecondary/current 这个目录中查看 SecondaryNameNode 目录结构。
SecondaryNameNode 的 namesecondary/current 目录和主 namenode 的 current 目录的布局相同。
好 处 : 在主 namenode 发生故障时( 假 设 没 有 及 时 备 份 数 据 ),可以从SecondaryNameNode 恢复数据。
- 5.8 Namenode 故障处理方法
- Namenode 故障后,可以采用如下两种方法恢复数据。
方法一:将 SecondaryNameNode 中数据拷贝到 namenode 存储数据的目录;
方法二:使用 -importCheckpoint 选项启动 namenode 守护进程 ,从而将 SecondaryNameNode 中数据拷贝到 namenode 目录中。
5.9 集群安全模式操作
:
- 概述
Namenode 启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的 fsimage 文件和一个空的编辑日志。此时,namenode 开始监听 datanode 请求。但是此刻,namenode 运行在安全模式,即 namenode 的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由 namenode 维护的,而是以块列表的形式存储在 datanode 中。在系统的正常操作期间,namenode 会在内存中保留所有块位置的映射信息。在安全模式下,各个 datanode 会向 namenode 发送最新的块列表信息,namenode 了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,namenode 会在 30 秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别( 默认值 : dfs.replication.min=1)。在启动一个刚刚格式化的 HDFS 集群时,因为系统中还没有任何块,所以 namenode 不会进入安全模式。 - 基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。- bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态) - bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态) - bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态) - bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
5.10 Namenode 多目录配置
:
- namenode 的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
- 具体配置如下:
1
2
3
4<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
6. DataNode 工作机制
6.1 DataNode 工作机制
:
- 一个数据块在 datanode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode 启动后向 namenode 注册,通过后,周期性(1 小时)的向 namenode 上报所有的块信息。
- 心跳是每 3 秒一次,心跳返回结果带有 namenode 给该 datanode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 datanode 的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器
6.2 数据完整性
:
- 当 DataNode 读取 block 的时候,它会计算 checksum
- 如果计算后的 checksum,与 block 创建时值不一样,说明 block 已经损坏
- client 读取其他 DataNode 上的 block。
- datanode 在其文件创建后周期验证 checksum
- 6.3 掉线时限参数设置
- datanode 进程死亡或者网络故障造成 datanode 无法与 namenode 通信,namenode 不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS 默认的超时时长为 10 分钟+30 秒。如果定义超时时间为 timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的 dfs.namenode.heartbeat.recheck-interval 大小为 5 分钟,dfs.heartbeat.interval 默认为 3 秒。
需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒。
1
2
3
4
5
6
7
8<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
- 6.4 DataNode 的目录结构
- 和 namenode 不同的是,datanode 的存储目录是初始阶段自动创建的,不需要额外格式化
- 在/opt/apps/Hadoop/hadoop-2.7.6/hdfs/data/current 这个目录下查看版本号
#Mon Jul 30 18:09:29 EDT 2018
storageID=DS-2967e493-97cf-4f11-88df-dee6ed3ca8bd
clusterID=CID-da97158f-34cc-4f8f-ad08-421c5fa542f7
cTime=0
datanodeUuid=624d7aa2-522b-48d0-bfb9-f5c3b80b77e0
storageType=DATA_NODE
layoutVersion=-56 - 具体解释
- storageID:存储 id 号 - clusterID 集群 id,全局唯一 - cTime 属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0;但是在文件系统升级之后,该值会更新到新的时间戳。 - datanodeUuid:datanode 的唯一识别码 - storageType:存储类型 - layoutVersion 是一个负整数。通常只有 HDFS 增加新特性时才会更新这个版本号。 - 查看该数据块的版本号
/opt/apps/Hadoop/hadoop-2.7.6/hdfs/data/current/BP-1314907513-192.168.100.100-1532659630649/current
namespaceID=1483942760
cTime=0
blockpoolID=BP-1314907513-192.168.100.100-1532659630649
layoutVersion=-56- 具体解释
- namespaceID:是 datanode 首次访问 namenode 的时候从 namenode 处获取的 storageID 对每个 datanode 来说是唯一的(但对于单个 datanode 中所有存储目录来说则是相同的),namenode 可用这个属性来区分不同 datanode。
- cTime 属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0;但是在文件系统升级之后,该值会更新到新的时间戳。
- blockpoolID:一个 block pool id 标识一个 block pool,并且是跨集群的全局唯一。当一个新的 Namespace 被创建的时候(format 过程的一部分)会创建并持久化一个唯一 ID。在创建过程构建全局唯一的 BlockPoolID 比人为的配置更可靠一些。NN 将 BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次 load 并使用。
- layoutVersion 是一个负整数。通常只有 HDFS 增加新特性时才会更新这个版本号。
- 具体解释
6.4 Datanode 多目录配置
:
- datanode 也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。
- 具体配置如下
1
2
3
4<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
6.5 节点的动态上下线
配置相应的ssh以及环境变量和Hadoop的配置文件,直接在新节点上启动就可以实现节点的动态上线(新节点的服役)
在namenode节点上,的hdfs-site.xml文件中增加一个属性
7. 文件定时上传
7.1 定时任务脚本
:
crontab命令格式
- 作用:用于生成cron进程所需要的crontab文件 - crontab -e 使用编辑器编辑当前的crontab文件具体的命令格式
1
2
3
4
5
6
7
8minute hour day-of-month month-of-year day-of-week commands
分 时 日 月 星期 要运行的命令
minute:表示一个小时中的哪一分钟 [0,59]
hour:表示一天中的哪个小时 [0,23]
day-of-month:一月中的哪一天 [1,31]
month-of-year:一年中的哪一月 [1,12]
day-of-week:一周中的哪一天[0,6] 0表示星期日
commands:要执行的命令注意事项
- 全都不能为空,必须填入,不知道的值使用通配符*表示任何时间
- 每个时间字段都可以指定多个值,不连续的值用“,”间隔,连续的值用-间隔。
- 命令应该给出绝对路径
- 用户必须具有运行所对应的命令或程序的权限
小案例
1
2
3
4
5
6
7
8
9
10
11
12
13案例1:每天4点备份
0 4 * * *
案例2:每周二,周五,下午6点 的计划任务
0 18 * * 2,5
案例3:1到3月份,每周二周五,下午6点的计划任务
0 18 * 1-3 2,5
案例4:周一到周五下午,5点45提醒员工15分钟后下班电脑自动关机
45 17 * * 1-5 /usr/bin/wall < /opt/message
0 18 * * 1-5 /sbin/shutdown -h now
案例5:公司的计划任务, 12点14点,检查apache服务是否启动
*/2 12-14 * 3-6,9-12 1-5每隔10秒执行一次
1
2
3
4
5* * * * * sleep 10; /bin/date >>/opt/test/date.log
* * * * * sleep 20; /bin/date >>/opt/test/date.log
* * * * * sleep 30; /bin/date >>/opt/test/date.log
* * * * * sleep 40; /bin/date >>/opt/test/date.log
* * * * * sleep 50; /bin/date >>/opt/test/date.log每隔1分钟产生一个日志文件,然后将文件上传至Hadoop集群
1
2
3
4!/bin/bash
filename=test-$(date +%Y%m%d%H%M%S).log
/bin/date > /opt/test/$filename
/opt/apps/Hadoop/hadoop-2.7.6/bin/hadoop fs -put /opt/test/$filename /logs/
8. Hadoop 归档
- 8.1 理论概述
- 每个文件均按块存储,每个块的元数据存储在 namenode 的内存中,因此 hadoop 存储小文件会非常低效。因为大量的小文件会耗尽 namenode 中的大部分内存。但注意,存储小文件所需要的磁盘容量和存储这些文件原始内容所需要的磁盘空间相比也不会增多。例如,一个 1MB 的文件以大小为 128MB 的块存储,使用的是 1MB 的磁盘空间,而不是 128MB。
Hadoop 存档文件或 HAR 文件,是一个更高效的文件存档工具,它将文件存入 HDFS 块,在减少 namenode 内存使用的同时,允许对文件进行透明的访问。具体说来,Hadoop 存档文件可以用作 MapReduce 的输入。
- 8.2 解决存储小文件方法之一
- Hadoop归档文件或har文件,是一个更高效的文件归档工具,它将文件存入HDFS块,在减少namenode内存使用的同时,允许对文件进行访问。具体来说,Hadoop归档文件对内还是一个个独立的文件,对namenode而言则是一个整体,减少了namenode的内存占用。
8.3 案例
:
启动 yarn 进程
将/logs/目录中的所有文件归档为一个叫testhar.har文件,并把归档后的文件存储在/目录下
1
hadoop archive -archiveName testhar.har -p /logs /
查看归档文件
1
2
3
4
5
6
7[root@master test]# hadoop fs -lsr har:///testhar.har
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 2 root supergroup 43 2018-07-31 22:32 har:///testhar.har/test-20180731223201.log
-rw-r--r-- 2 root supergroup 43 2018-07-31 22:36 har:///testhar.har/test-20180731223602.log
-rw-r--r-- 2 root supergroup 43 2018-07-31 22:37 har:///testhar.har/test-20180731223701.log
#解归档
[root@master data]# hadoop fs -cp har:///test/test.har /my
9. 回收站配置
修改 core-site.xml,配置垃圾回收时间为 10 分钟。
1 | <property> |
修改访问垃圾回收站用户名称
进入垃圾回收站用户名称,默认是 dr.who,修改为 root 用户
1 | <property> |
通过程序删除的文件不会经过回收站,需要调用 moveToTrash()才进入回收站
1 | Trash trash = New Trash(conf); |
恢复回收站数据
1 | hadoop fs -mv /user/root/.Trash/Current/aaa.log / |
清空回收站
1 | hdfs dfs -expunge |