Hadoop-Flume
Flume简介
- Flume提供了一个分布式的,可靠的,对大数据量的日志进行高效的收集,聚集,转移的服务,只能在Linux下使用。
- 基于流式框架,容错性腔,比较灵活简单
- 可以用对数据进行实时采集,Kafka(卡弗卡)实时采集。Spark,Storm对数据进行实时的处理。impala对数据进行实时的查询。Hive做离线数据处理,MR离线数据处理。
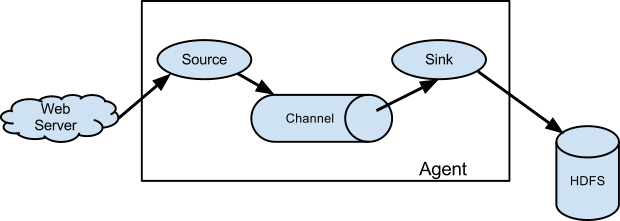
Flume的架构
- ![image_1cl070n9v11gkg9h13fh1tbs1k619.png-22.8kB][1]
Source - 用于采集数据,简单来说就是和数据的来源进行对接,然后将采集的数据流传输到Channel。
- Channel
- 简单来说就是将Source和Sinks连接起来,类似于一个队列
- Sink
- 从Channel采集数据,然后将数据写到目标(可以使Source,也可以是HDFS,HBase等等)
- Event
- 数据的传输单元。也就是事件,类似于Java中的bean类。
- 数据传输
- source 可以监控某个文件或数据流,或端口等等,一旦数据源产生新的数据,拿到数据后,将数据分装成一个事件(Event),然后放入(put)到 Channel 中然后(Submit)提交,Channel 队列先进先出,Sink就去Channel 队列拉去数据,然后写入到目标中(HDFS或者其他的目标)
Flume安装
- 下载
- [下载地址][2] http://flume.apache.org/download.html
- 解压
1
2[root@master Flume]# tar -zxvf apache-flume-1.8.0-bin.tar.gz
[root@master Flume]# mv apache-flume-1.8.0-bin flume-1.8.0
- 修改配置
1
2
3
4
5
6
7
8
9
10
11[root@master conf]# cp flume-env.sh.template flume-env.sh
[root@master conf]# vim flume-env.sh
# 添加以下内容
export JAVA_HOME=/opt/apps/Java/jdk1.8.0_172
export FLUME_HOME=/opt/apps/Flume/flume-1.8.0
export FLUME_CLASSPATH=$FLUME_HOME/lib
[root@master conf]# vim /etc/profile
Flume环境变量
export FLUME_HOME=/opt/apps/Flume/flume-1.8.0
export PATH=$PATH:$FLUME_HOME/bin
Flume实操
案例1:监控端口的数据流
- 安装 telnet 工具
1
[root@master conf]# yum install telnet
- 创建Flume的agent配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23[root@master flume]# vim flume-telnet.conf
配置agent中的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
配置source
a1.sources.r1.type = netcat
a1.sources.r1.bind = master
a1.sources.r1.port = 6666
配置sink
a1.sinks.k1.type = logger
配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
建立联系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 运行端口和Flume监控
1
2
3
4
5
6
7
8# 启动Flume
[root@master flume]# flume-ng agent \
--conf conf \
--conf-file ./flume-telnet.conf \
--name a1 \
-Dflume.root.logger==INFO,console
# 往端口中写数据
[root@master conf]# telnet master 6666
案例2:实时读取本地文件到HDFS
监控Hive的日志文件,将日志文件的内容上传到HDFS
- 创建相应的配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39[root@master flume]# vim flume-hdfs.conf
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /tmp/root/hive.log
# sink
a2.sinks.k2.type = hdfs
文件上传的HDFS路径
a2.sinks.k2.hdfs.path = hdfs://master:9000/flume/%
m-%d/%H-%M
文件的前缀
a2.sinks.k2.hdfs.filePrefix = hive-log-
是否按照时间滚动产生新的文件夹
a2.sinks.k2.hdfs.round = true
按照多长时间滚动一次
a2.sinks.k2.hdfs.roundValue = 1
时间的单位
a2.sinks.k2.hdfs.roundUnit = minute
滚动产生新的文件
a2.sinks.k2.hdfs.rollInterval = 30
a2.sinks.k2.hdfs.rollSize = 125829120
设置事件多少个之后产生新的文件
a2.sinks.k2.hdfs.rollCount = 30
a2.sinks.k2.hdfs.fileType = DataStream
hdfs.minBlockReplicas这个就是block块的数目
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#Channel
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
#关联
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
案例3:实时目录文件到HDFS
- 配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42[root@master flume]# vi flume-dir.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/test/flume/dir
a3.sources.r3.includePattern 包含哪些文件,后面跟的 .log
是正则表达式
a3.sources.r3.ignorePattern 忽略哪些文件 .tmp
# sink
a3.sinks.k3.type = hdfs
文件上传的HDFS路径
a3.sinks.k3.hdfs.path = hdfs://master:9000/flume/dir
/%y-%m-%d/%H-%M
文件的前缀
a3.sinks.k3.hdfs.filePrefix = dir-
是否按照时间滚动产生新的文件夹
a3.sinks.k3.hdfs.round = true
按照多长时间滚动一次
a3.sinks.k3.hdfs.roundValue = 1
时间的单位
a3.sinks.k3.hdfs.roundUnit = hour
滚动产生新的文件
a3.sinks.k3.hdfs.rollInterval = 300000
a3.sinks.k3.hdfs.rollSize = 125829120
设置事件多少个之后产生新的文件
a3.sinks.k3.hdfs.rollCount = 0
a3.sinks.k3.hdfs.fileType = DataStream
hdfs.minBlockReplicas这个就是block块的数目
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#Channel
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
#关联
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
注意:
- 上传完成的文件是以.COMPLETED结尾,这个是可以修改的
- 上传文件的目录会默认每隔500毫秒扫描一次。pollDelay
- 上传文件的时候经常使用重命名操作
案例4:一个source多个sink
1 | [root@master flume]# vi flume-more.conf |
案例5:一个agent到多个agent输出
Flume1监控文件的变动,Flume1讲述传递给Flume2,Flume2将数据写到HDFS,Flume1还会将数据传递给另一个Flume3,然后Flume3将数据的变化输出到本地。
1 | # Flume1 |
作业
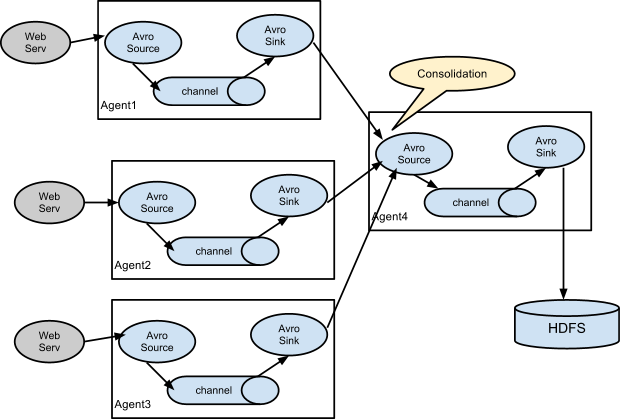
多对1
![image_1crpb15pe4vt1ks76fe1e731k8p9.png-60.3kB][3]
总结Flume中的参数
1 | Cannot stream to table that has not been bucketed |