深入浅出—大数据
第1章 小结
1、大数据产业生态划分为三个层次:
a. 大数据应用:
企业开发出来的一些通用应用,例如:大数据可视化和分析数据、大数据商业智能工具或数据服务等
b. 大数据基础设施:
指的是PaaS层的基础设施,如数据采集、存储、数据集成、数据并行处理和数据分析等基础的 平台层能力
c. 大数据技术:
包括了数据采集、数据存取,数据处理,统计分析,数据挖掘,模型预测,结果呈现等技术。
目前,Hadoop已经确立了其作为大数据生态系统基石的地位。且Hadoop是由Java实现的,它可以对分布式环境下的大数据以一种可靠、高效、可伸缩的方式处理
大数据的关键特征
关键特征分别是:
- 数据量大(全球信息量几十万亿GB)、
- 数据类型多(其中80%是非数据结构化占比)、
- 处理速度快(达到秒级甚至毫秒级处理速度)
- 数据价值(数据价值高,价值密度低)
小知识点:
- 结构化数据:关系型数据库数据以及面向对象数据库中的数据。
- 半结构化数据:HTML,XML,各类报表等
- 非结构化数据:音频、视频等
数据思维
- 传统数据思维,是在在定义问题的时候有一定的假设,然后通过各种方式来证明这一假设是否正确。
- 大数据思维:是没有预知的假设,而是使用归纳推理的方法,从部分到整体的进行观察描述,通过问题存在的环境观察和解释现象,从而起到预测的效果。
数据处理
- 传统的数据处理:处理结构化或者关系型数据。且使用昂贵的硬件设备(小型计算机+磁盘列阵)或者一体机来完成数据分析处理挖掘的。
- 大数据处理是具备结构化、半结构化、非结构化混合处理的能力。数据的采集一般是存储在关系型数据库Oracle、非关系型数据库NoSQL、分布式文件系统HDFS,将这些多种类型的数据可通过并行计算(MapReduce、Spark)来提高数据处理的速度。
小结:且大数据的硬件要求不高,使用x86作为分布式平台搭建的基础服务器,搭建高可用后,平台兼容性好,可扩展性高,无需高性能高可靠性的硬件。
注:mapReduce是通过大量廉价服务器实现大数据的并行处理,且对数据的一致性不高,扩展性和可用性高,适用于海量的结构化、半结构化和分结构化的混合处理。数据分析
. | 传统数据分析 | 大数据分析 - |-|-
分析对象 | 部分数据的采样 | 全部数据 |
分析类型 | 结构化数据 | 结构化、半/非结构化数据 |
精确性 | 精准、规范化的数据 | 无特别要求 |
分析算法|对算法要求比较高|算法简单有效|
分析结果|注重因果关系|更注重相关性|
数据治理
是贯穿整个大数据的生命周期的系统全面的方法。
大数据的数据治理包括
- 隐私性
- 安全性
- 合规性
- 数据质量
- 元数据管理
- 主数据管理
- 集合业务特点的延伸(具体问题具体分析)
- 数据维度化:加强大数据应用的安全起源,明确数据认责
- 强制访问控制的保密要求,适当地屏蔽个人或组织隐私信息等措施。
- 治理目标:是否明确定义,明确责任方,数据内容是否符合标准要求,数据的存储与管理,数据分析,数据访问安全控制等方面进行制定。
被动安全机制
大数据安全不仅限于大数据基础设施的方案,还要考虑到数据采集、大数据分析、大数据基础架构本身的安全。
大数据关键技术
数据采集工具介绍
Flume
Flume是一个高可用的,高可靠的,分布式的海量日志采集聚合和传输的系统。支持对数据进行简单的处理,并写到各种数据接受方的能力。
source源主要可以从console(控制台)、RPC(Thrift_RPC)、text(文件)、tail、syslog(日志系统支持TCP和UDP)、exec(命令执行)等数据源上收集数据的能力。
Scribe
Facebook开源的日志收集系统,主要特点是容错性好,从各类数据源收集的数据,放到一个共享队列里,然后Push到后端的中央存储系统上,当存储系统出现故障后,Scribe可以暂时将数据(日志)存放到本地文件中,待中央存储系统恢复性能后,Scribe把本地日志续传到中央存储系统上。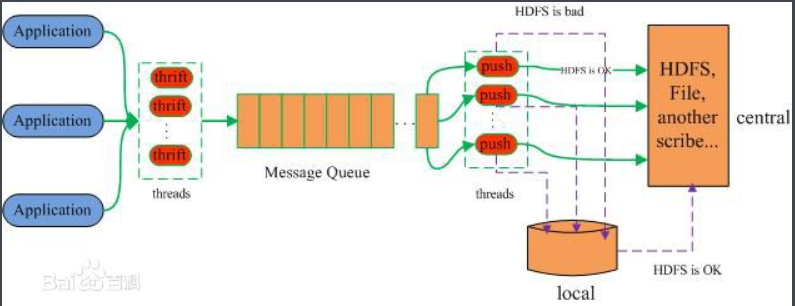
注:Buffer:是最常用的一种存储方式。包含两个子存储,其中一个是主存储(在此指中央存储系统),另一个是辅存储(在此指本地文件),日志数据优先存放在主存储中,如果主存储出现故障,则Scribe会将数据暂存放在辅存储中,待主存储恢复性能后,再将辅存储中的数据复制到主存储中。其中辅存储仅支持两种存储方式,一个是File(本地文件)一个是HDFS。
Kafka
Kafka是用Scala开发的分布式消息订阅发布系统,主要有三种角色,分别为生产者(producer),代理(Broker)和数据消费者(Consumer)。生产者向指定Topic发布(Push-推)消息,而Consumer订阅(pull-拉)指定Topic的消息,进而一但这个指定的Topic里面有数据,Broker(代理)就会将数据信息传递给订阅该Topic的所有Consumer。
注: Topic有多个partition便于管理数据进行负载均衡。
Time tunnel
是阿里巴巴的一个高效的、可靠的、可扩展的的实时数据传输平台,支持消息多用户订阅。主要功能就是实时完成海量数据的交换,因此它的业务逻辑主要有两个,一个是将发布数据至Time Tunnel,一个是从Time Tunnel订阅数据。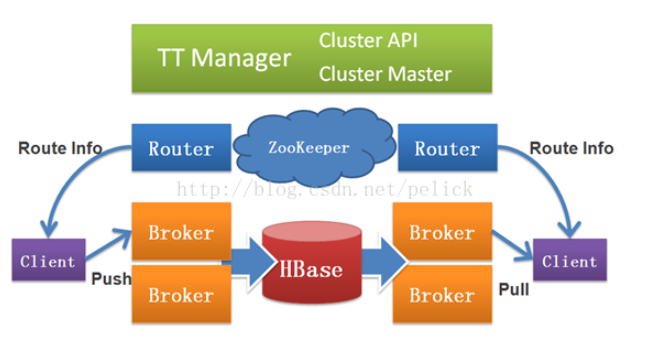
组件介绍:
Time Tunnel大概由TT Manager、Client、Router、Zookeeper和Broker几个部分组成。
- TT Manager:对外提供队列申请、删除、查询和集群的管理接口:对内 故障发现,发起队列迁移。
- Client:是一组访问Time Tunnel的API,主要由安全认证API、发布API和订阅API(目前api支持JAva、Python、PHP)
- Router是访问Time Tunnel的门户,负责路由、安全认证和负载均衡,为客户端提供路由信息,找到为消息队列提供服务的Broker.
- Zookeeper是Hadoop的开源项目,主要功能是状态同步,Borker和Clienter的状态都存储在这里。
- Broker是Time Tunnel的核心,负责消息的存储转发,承担实际流量,进行消息队列的读写。
操作流程:
Client访问Time Tunnel的第一步是向Router进行安全认证,如果认证通过,Router会根据Client要发布或者要订阅的topic对Client进行路由(负载均衡保证让所有的broker平均地接收Client访问),使的Client和Broker进行连接。
Chukwa
是一个开源的用于监控大型分布式系统的数据收集系统,是构建在Hadoop的HDFS和Map/Reduce框架之上的。包含一个灵活的工具集,用于展示、监控和分析以收集的数据。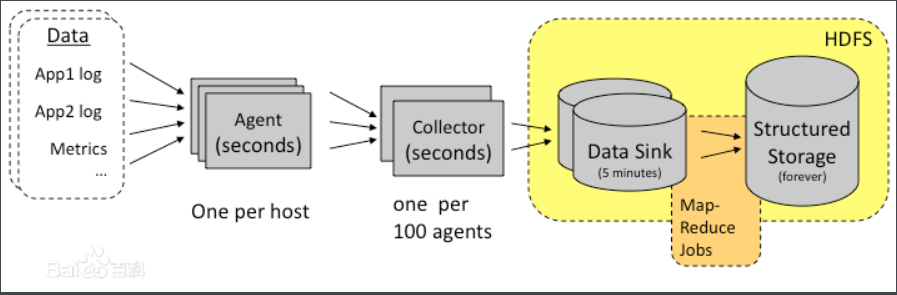
大数据存储与管理技术
| . | 结构化数据 | 半结构化数据 | 非结构化数据 |
|---|---|---|---|
| 定义 | 有数据结构描述信息的数据 | 介于完全结构化数据和完全非结构化数据之间的数据 | 无固定结构来表现的数据 |
| 特点 | 先有结构,再有数据 | 先有数据再有结构 | 只有数据,没有结构 |
| 存储 | 分布式关系型数据库 | 分布式文件系统 | 分布式非关系型数据库 |
| #### 分布式文件系统 | |||
| 1. Consistency(一致性):文件系统中的所有数据备份在同一时间是否是同样的值。 | |||
| 2. Availability(可用性):部分出错,是否会影响其他大部分的运作。 | |||
| 3. Partition Tolerance(分区容错性):约束了一个分布式系统需要具有如下特性,分布式在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。 |
未完待续。。。