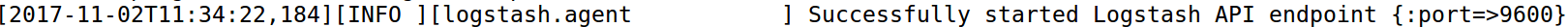ELK安装文档
1. 安装准备
1.1 操作环境
操作系统环境:Centos7 1708版本
JDK版本:jdk-8u144-linux-x64.tar.gz
Elasticsearch版本:5.6.3
Logstash版本:5.6.3
Kibana版本:5.6.32. 安装上传文件和下载文件的插件(可以不安装)
鉴于Elasticsearch用户只能是非root用户,因此后面的所有操作都在es账户下执行
1 | [root@master ~]# yum -y install lrzsz |
3. 安装sudo命令并配置
由于这里采用的是最小化安装,因此sudo命令不可用。
3.1 安装sudo插件
1 | [root@master ~]# yum -y install sudo |
3.2 修改/etc/sudoers文件的权限
1 | [root@master ~]# chmod u+w /etc/sudoers |
1 | package com.zhiyou100.abstrac; |
3.3 开始编辑/etc/sudoers文件
1 | [root@master ~]# vi /etc/sudoers |
3.4 找到root ALL=(ALL) ALL行,在下面添加如下内容
1 | es ALL=(ALL) NOPASSWD: ALL |
3.5 去掉#%wheel ALL=(ALL) NOPASSWD: ALL的#号
3.6 保存并退出
3.7将es用户调整至wheel用户组中,这样以后使用sudo命令的时候就不用输入密码了。
1 | [root@master ~]# gpasswd -a es wheel |
3.8 恢复/etc/sudoers文件的权限
1 | [root@master ~]# chmod u-w /etc/sudoers |
然后你就可以肆无忌惮的使用es用户了
#4. 切换至es用户
1 | [root@slave3 ~]# su es |
#5. 创建相应目录
1 | [es@master ~]$ sudo mkdir -p /opt/SoftWare/Java |
#6. 关闭防火墙
1 | [es@master Java]$ sudo systemctl stop firewalld |
#7. 安装jdk环境
7.1 上传tar包
1 | [es@master Java]$ sudo rz |
7.1 卸载JDK
7.2 解压jdk
1 | [es@master Java]$ sudo tar -zxvf jdk-8u144-linux-x64.tar.gz |
7.3 配置环境变量
1 | [es@master Java]$ sudo vi /etc/profile |
添加一下内容:
1 | JDK1.8 |
使修改生效
1 | [es@master Java]$ source /etc/profile |
7.4 将master节点上的jdk远程拷贝到其他节点上
1 | [es@master Java]$ sudo scp -r jdk1.8.0_144 root@192.168.100.101:/opt/SoftWare/Java/ |
#8. Elasticsearch的安装
Elasticsearch的安装比较简单,但是有一些细节要注意,在这里咱们采用tar包进行安装
8.1 将Elasticsearch上传至VM
可以在命令行中输入rz调出上传窗口即可:如[root@master ES]# rz。
8.2 解压Elasticsearch压缩包
1 | [root@master ES]# tar zxvf elasticsearch-5.6.3.tar.gz |
8.3 创建相关目录并赋权限给es
1 | [root@master ~]# mkdir -p /var/elasticsearch/log |
8.4 配置核心文件
1 | ################################## Cluster ################################### |
一般情况下,配置以下内容即可:编辑elasticsearch.yml文件
1 | [root@master config]# vi elasticsearch.yml |
8.5 配置JVM
1 | [root@master config]# vi jvm.options |
8.6 配置数据节点
很明显,前面那一台节点咱们设置的是不存储数据的,一般来说咱们都会固定master节点,如果条件允许,可以多设置几台都行。在这里,我只配置了一台master节点,其余的三个节点设置为数据节点
在master节点上使用远程拷贝将elasticsearch主目录拷贝到其他节点上
1 | [root@master ES]# scp -r elasticsearch-5.6.3 root@192.168.100.101:/opt/SoftWare/ES/ |
在数据节点上修改相关配置,其余的可以不修改了
1 | 节点名称 |
8.7 给数据节点创建相关目录并赋权限给es
1 | [root@master ~]# mkdir -p /var/elasticsearch/log |
8.8 修改系统配置文件(每台节点均需要配置并重启生效)
1 | 编辑文件1:/etc/security/limits.conf |
8.9 可能的错误集锦:
8.9.1 can not run elasticsearch as root
1 | 错误详情: |
8.9.2 Unable to lock JVM Memory: error=12, reason=无法分配内存
1 | 错误详情: |
8.9.3 ERROR: [1] bootstrap checks failed
1 | 错误详情: |
8.9.4 ERROR: [1] bootstrap checks failed
1 | 错误详情: |
8.9.5 access denied (“javax.management.MBeanTrustPermission” “register”)
1 | 错误详情: |
8.10 测试集群环境是否搭建成功
1 | 每台节点都进入到es主目录,使用es用户 |
#9. 安装Head插件
9.1 下载
9.2 解压
由于最小化安装,故没有解压zip文件的命令,首先安装unzip解压软件,然后再进行解压
1 | [es@master plugins]$ sudo yum install zip unzip |
9.3 安装HTTP
由于这个插件就是HTML5写的,就是一个前端的一个东西,只需要set到HTTP服务中即可
1 | 安装HTTP |
9.4 复制head到HTTP的指定目录
1 | [es@master ~]$ cd /var/www/html |
9.5 启动ES集群和HTTPD服务
1 |
|
访问IP地址如下说明已经启动,可以设置开机自启
![image_1btt80jm0qspmmrk121ksqp559.png-555.7kB][1]
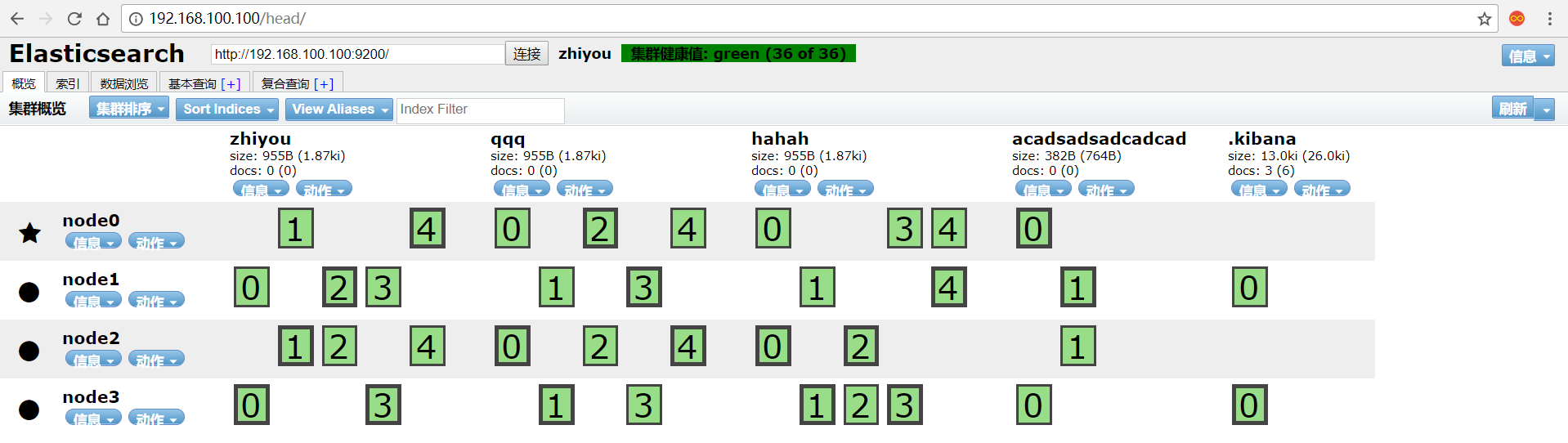
1 | 启动ES集群 |
出现下面的类似界面
![image_1btt9a90v8qaqfo1a5i130htnm.png-111.2kB][2]
10. 安装Kibana
10.1 下载
10.2 解压
1 | [root@master Kibana]# tar kibana-5.6.3-linux-x86_64.tar.gz |
10.3 配置
1 | [root@master Kibana]# cd kibana-5.6.3 |
10.4 启动Kibana
1 | [root@master kibana-5.6.3]# bin/kibana |
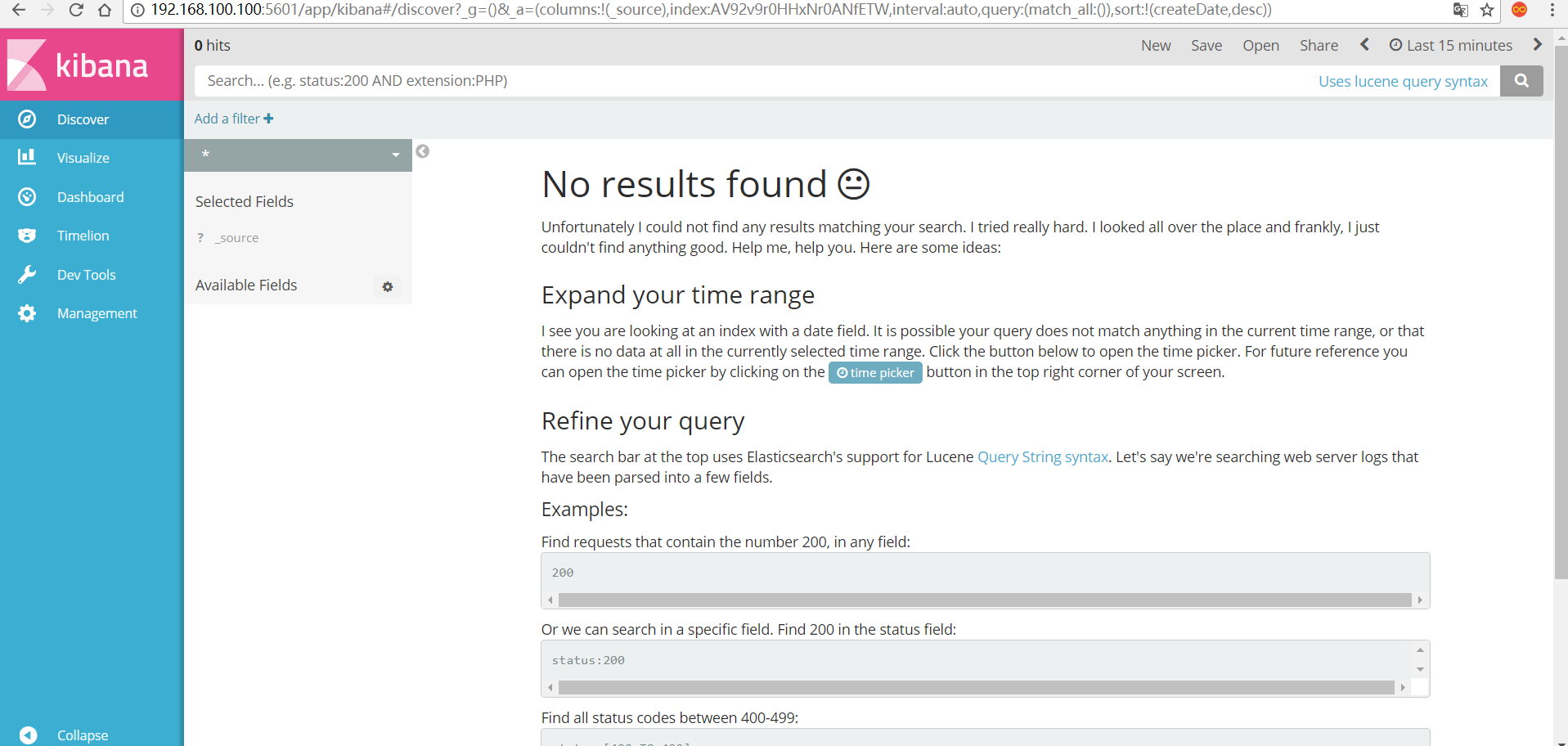
出现下面的界面,可能会因为数据的问题有点不一样
![image_1btta457a3d01e371c3fn3c1dav13.png-45.8kB][3]
![image_1btta50r5vikqra135r1dv7lfp20.png-199.8kB][4]
第一次启动会提示配置一个索引,其实就是默认的一个搜索位置
11. 安装Logstash
11.1 下载Logstash
11.2 解压缩
1 | [root@master Logstash]# tar -zxvf logstash-5.6.3.tar.gz |
11.3 运行Logstash
1 | 在这里可以使用标准输入线测试一下logstash |
出现下面的内容说明启动成功
![image_1bttcndg518kq1enu8tg3v14f32d.png-16.1kB][5]
然后练习以下输入输出
11.3.1 codec
1 | [root@master logstash-5.6.3]# bin/logstash -e 'input { stdin{} } output {stdout{codec => rubydebug} }' |
![image_1bttcvo60152g36i5oa19ei1u7v2q.png-45.7kB][6]
11.3.2 输出es集群中
注意:老版本和新版本不同,注意看官方文档
1 | [root@master logstash-5.6.3]# bin/logstash -e 'input { stdin{} } output {elasticsearch { hosts => ["192.168.100.100:9200"] } stdout{} }' |
12. 使用ELK进行整合操作
12.1 编写数据读取的配置文件
1 | [root@master logstash-5.6.3]# vi /var/logstash/config/std.conf |
添加如下内容
1 | input { |
应用
1 | [root@master logstash-5.6.3]# bin/logstash -f /var/logstash/config/std.conf |
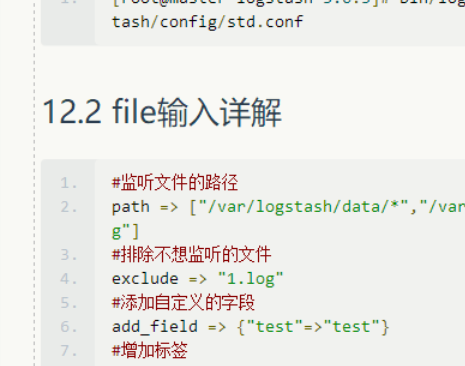
12.2 file输入详解
1 | 监听文件的路径 |