Bloom filter 布隆过滤器
算法:
- 首先需要k个hash函数,每个函数可以把key散列成为1个整数
- 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
- 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
- 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
优点:
不需要存储key,节省空间
缺点:
- 算法判断key在集合中时,有一定的概率key其实不在集合中
- 无法删除
典型的应用场景:
某些存储系统的设计中,会存在空查询缺陷:当查询一个不存在的key时,需要访问慢设备,导致效率低下。
比如一个前端页面的缓存系统,可能这样设计:先查询某个页面在本地是否存在,如果存在就直接返回,如果不存在,就从后端获取。但是当频繁从缓存系统查询一个页面时,缓存系统将会频繁请求后端,把压力导入后端。
具体应用实例
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样: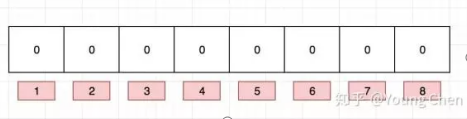
映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
结果:1 如果有一个获取的hash值为0的话那就代表该向量中没有这个数据。但如果都为1的话,只能代表该bit向量中可能含有该数据,但由于hash函数后的函数值是重复迭代在向量中为1的,因此不一定含有该数据。
bitmap 位图
根据数据数量来定义向量位数,初始值都为0,进行遍历,如果有当前位数的话,在其位置标记为1,
优点
缺点