Spark
可使用Java、Scala、Python、R和Sql 快速编写应用程序
rdd
(Resilient Distributed Datasets)弹性分布式数据集
- 弹性:表示数据是可恢复的 可容错
利用的是血缘(依赖)关系 - 分布式:数据来源于分布式集群(如 hdfs,hbase,kafka)
- 数据集: 数据组织成一个集合(List)
spark 运行模式:
- local本地模式 local[n] n表示使用n个线程,如果使用local[*]表示根据cpu核数确定,一般用于测试
- standalone spark集群模式,需要搭建spark集群 例如:spark://192.168.200.129:7777…
- yarn模式 不需要搭建spark集群,直接将spark应用提交到yarn运行。类似于mapreduce
- mesos k8s。。。。。
rdd操作
sc=sparkcontext
- 加载数据转换成rdd —spark操作的对象是rdd,因此需要把相关集合对象转换成rdd
1 | val data = Array(1, 2, 3, 4, 5) |
- 默认获取的数据会被分布式的存储在多个分区中,除非在sc下的方法中增加分区数量如:(,1)
- rdd数据源的两种,
a. paralize
b. 外部数据源
textFile:spark记载rdd是lazy懒加载,也就是计算发生的时候才去加载,可以传入通配符,读取目录下所有的文件机或者压缩文件,默认情况下,一块就是一个分区,可以让分区大于快熟,不能让分区少于快数
1 | scala > al rdd5=sc.textFile("hdfs://192.168.200.129:9000/hbase/MasterProcWALs/state-00000000000000000009.log") |
tranformations:由rdd生成新的rdd 如 map filter groupby reducebykey
actions :由rdd生成,返回一个结果reduce saveasTextFile foreach count
注:对于转换次数比较多的rdd可以使用cache(persist方法,将rdd缓存到内存中,以空间换时间,减少计算时间)。
job-任务运行的部分
当rdd运行到action方法时(reduce、 SaveAsTextFile、foreach count),会触发job的运行。
由sparkcontext向spark集群提交job
stage:
- spark将job划分成1到多个stage
- stage与stage之间通过shuffle划分
注:如果在job过程中出现shuffle 就会划分成新的stage - 发生shuffle的情况有:group by ,reduce by key , join ,distinct….
stage里是不会发生shuffle,但在stage与stage可能会发生shuffle操作
suffle操作相当于有网络通信
stage内部计算是并行的 不会发生网络通信
stage之间计算时串行的 会发生网络通信
注: shuffle执行,就会多一个stage action执行就是一个job job一定比stage少, stage一定等于或多于job 一个job可以包含一个或者多个stage
task
一个分区上的一次计算称为task
多个task组成stage
driver
driver 运行sparkcontext的应用,用于做任务job的提交
executor
executor:运行任务,对数据进行具体的计算
闭包
闭包:函数访问了外部的变量
driver里的代码是没有进行对数据做处理的代码是driver,executor 如果调用了driver的变量就会出错 形成闭包的状态
{ driver
val conf=new SparkConf()
//设置app的名字
.setAppName(“demo”)
//设置spark运行模式 这里以local为例
.setMaster(“local[2]”)
val sc=new SparkContext(conf)
} { executor
val rdd=sc.parallelize(Range(1,10000),4)
Thread.sleep(10000)
}
spark Java Api
新建一个maven或者Java项目,然后新建一个文件scala 于原本的资源包同目录,然后设置该scala文件为资源包,且右击项目→_→ AddFramework support→_→ 在左侧菜单栏选择scala →_→选择应用 这样就可以使用scala的class以及object了
1 | package com.day01 |
Api
transformations
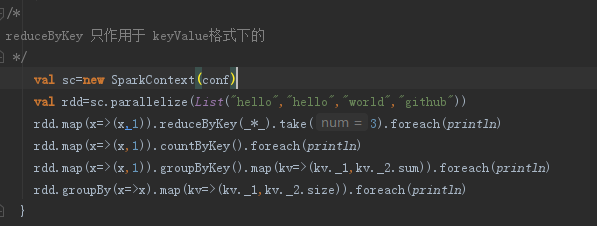
- map
- reduceByKey
- groupByKey
- Api高性能算子-mapPartition
某些情况下需要频繁的创建和销毁资源,高性能算子可以在只在分区上创建或销毁。不用在每个
元素上创建或销毁。提升了性能。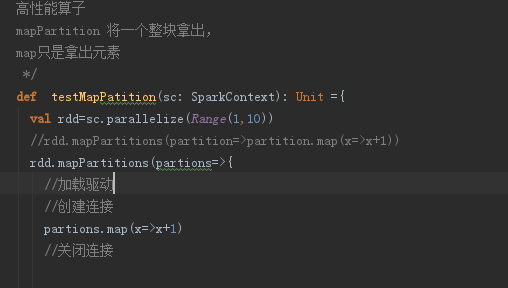
- mapPartitionWithindex 再给你个索引下标
- sample 抽样
- union 并集
- intersection 交集
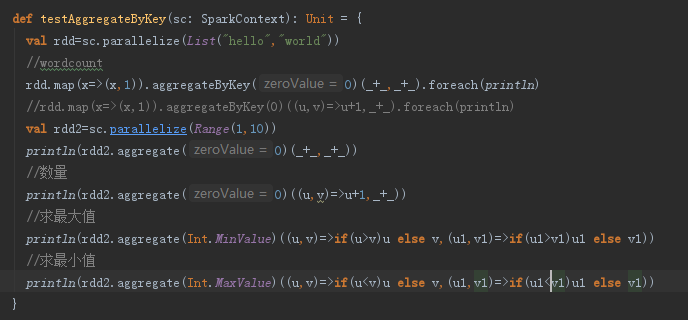
- aggregateByKey 聚合 分为三段:
- 给定初始值,
- 进行分块聚合运算,
- 块与块之间的聚合运算
- sortByKey 按key排序
- join
- cogroup 分组
- cartesian 笛卡尔积
- coalesce 合并 减少rdd分区的数量 过滤大型数据集后,可以更有效的运行操作
- repatition 重新分区 随机重新分区,增加或者减少分区数量,进行平衡 用于数据倾斜
默认是has分区 但使用has分区-相同的key一定分到一个分区
actions
1111
Spark 应用
spark 应用提交与部署
spark应用部署到yarn有两种模式
cluster:driver运行在集群的某一台主机上
client:driver运行在客户端
首先 在idea中编译好自己的jar包之后
pom.xml中 加入
scala代码
注意需要注释掉spark的运行模式,因为后面会直接使用在yarn上
且在最后要写好 输出到什么地方
1 | package day02 |
打包前需要在pom.xml中加入下列代码以防scala代码不编译
1 | <build> |
然后再maven里clean后 点M字符的命令行,

再选中需要导入的模块项目 打入以下命令-
clean scala:compile compile package -DskipTests=true
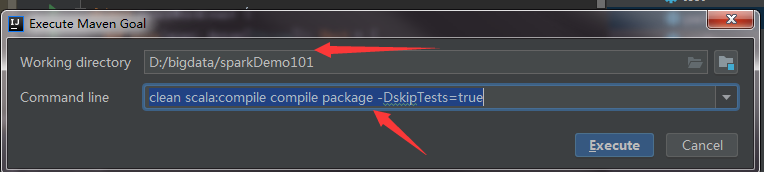
首次加载需要下载很多东西,稍等一会,然后完成后就可以打包了
打包完成之后放入linux /tmp/spark目录下
然后进入spark bin目录下
spark-submit --class day02.SparkWordCount --master yarn --deploy-mode cluster /tmp/spark/sparkDemo101-1.0-SNAPSHOT.jar
注:如果运行报错没有权限的话,在当前目录下输入
chmod +x -R ./*
运行最后出现以下,则为正确
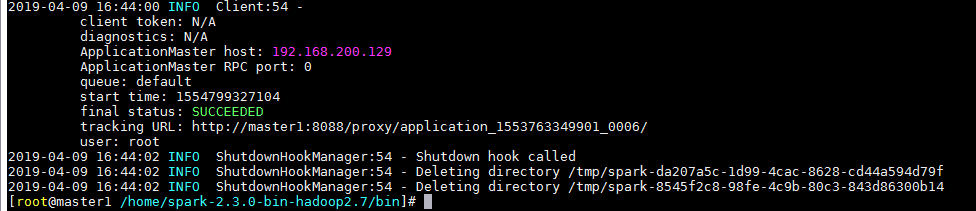
然后可进入ip:8088 查看状态
全局变量
广播变量:
可以再exector中使用,可以分发给各个分布式节点使用,但不能修改
作用:一般用于大小表的join,小标广播能够节省网络传输,避免shuffle map join
实用于广播维度表给事实表使用
累加器
作用于driver, exector只有向driver发送累加请求,由driver进行累加
窄依赖 宽依赖
窄依赖:子rdd的一个分区,只依赖与父rdd的一个分区
宽依赖:子rdd的一个分区 依赖于父rdd的多个分区
区分的关键在于shuffle
不发生shuffle是窄依赖,发生shuffle是宽依赖
rpc 远程方法调用
传输通道
socket网络通信
客户端
动态代理
服务端
反射
客户端 client.java
这是一个远程累加器的服务端客户端的案例 注意看客户端的前段注释理解!
1 | package com.day03.rpc; |
服务端 server.java
1 | package com.day03.rpc; |
方法的接口 Acc
1 | package com.day03.rpc; |
方法 AccImp.java
1 | package com.day03.rpc; |
request和response
1 | package com.day03.rpc; |
Spark SQL
sql 命令行
DataFrames
在spark bin目录下打开,命令行窗口 输入.\spark-shell –master local[2]
进入scala命令行
1 | scala > val df = spark.read.json("../examples/src/main/resources/people.json") |
sql 案例代码
注:本地连接虚拟机的mysql出现拒绝连接的问题 此时给其授权
grant all privileges on . to root@’%’ identified by “gxyzxf”;
flush privileges;
1 | package com.day03 |
运行结果

rdd-数据类型
dataframe
就是给一个rdd加一个模式 使其结构化
sparksession
sparkcontext
例如 sparksession.sparkcontext
dataset
当使用api操作数据的时候,建议使用dataset
当通过sql操作的时候,两种都行
自定义函数
1 | package day04 |
小结
针对以上代码进行小结
rdd
数据文件直接new SparkContext().textFile(“//“) 将文件读取进来 成为rdd
或者自定义集合数组成为rdd new SparkContext().parallelize(List(“”))
在rdd弹性分布式结果集中可以使用api进行调用
dataFrame dataSet
两种数据类型
- 将结构化文件通过SparkSession.read.api(“//“) 注:api里得有相应的格式
- 非结构化的文件只能先通过textfile 成为rdd ,然后导包 import spark.implicits._隐式转换的形式,再rdd().toDF 或者rdd().toDS 将rdd转换成dataFrame或者dataSet
- 建立的集合也是同2需要从rdd进行转换
sparkcontext rdd
sparksession dataframe dataset
sparkstreaming dstream
dataFrame 针对于sql方式操作的
dataSet 通过面向对象进行的操作的
大数据处理的两种:
实时/流处理(real-time):
数据的产生于数据的计算完成相隔时间很短,大约在秒级
sparkstreaming /storm
SparkStreaming
一般SparkStreaming 配合kafka使用 一方面原因是因为利用kafka的缓存通道,
sparkstreaming 有状态计算
状态:一个动态的属性 如累计
checkpoint
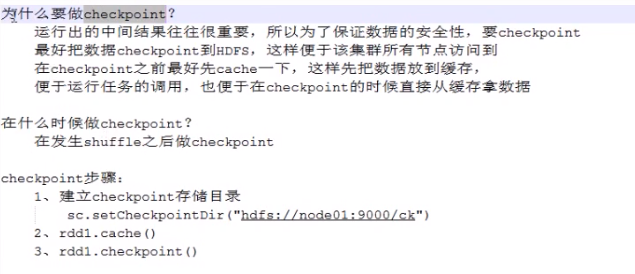
UpdateStateByKey 状态计算
注:如果报错java.lang.NoSuchMethodError: net.jpountz.lz4.LZ4BlockInputStream
原因:应用在执行时对数据解码(反序列化)时,使用了默认的lz4解压缩算法,在spark-core中依赖的lz4版本是1.4,而kafka-client中依赖的lz4版本是1.3版本,在生成解压器时,版本不兼容异常。
解决方法:
- conf = SparkConf().set(“spark.io.compression.codec”, “snappy”)
- pom.xml
1
2
3
4
5
6
7
8
9
10
11<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<exclusions>
<exclusion>
<artifactId>lz4</artifactId>
<groupId>net.jpountz.lz4</groupId>
</exclusion>
</exclusions>
<version>2.3.0</version>
</dependency>
窗口计算
计算最近一段时间的数据运算
离线处理(off-line):
存储后处理 时间间隔长 mapreduce hive spark sparksql …..
Parquet?