Hbase基础理论
HBase以表的形式存储数据。表有行和列组成。划分为若干个列族。
1.HBase简介
Hbase是什么?
Hbase是一个高可靠性、高性能、列存储、面向列、可伸缩、实时读写的分布式存储系统,利用HBASE技术,可以让我们在廉价便宜的PC Server上搭建大规模结构化存储的集群。
HBase仅需使用普通的硬件配置,就可以能够处理,由成千上万的行和列所组成的大型数据库(非关系型数据库)
存储形式
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(column-family)。

Hbase与Hdfs的关系
Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据存储文件夹的结构。
Hbase与MR的关系
Hadoop可以通过Map/Reduce的框架(算法)对HBase进行操作。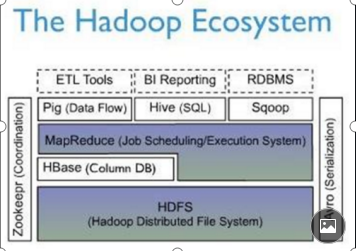
#1
HBase的几大组件
HMaster
功能:
- 监控RegionServer
- 处理RefionServer故障转移
- 处理元数据的变更
- 处理region的分配和移除
- 在空闲时间进行数据的负载均衡
- 通过Zookeeper发布自己得位置给客户端
RegionServer
功能:
- 负责存储HBase的实际数据
- 处理分配给它的Region
- 刷新缓存到HDFS
- 维护HLog
- 执行压缩
- 负责处理Region分片
其他组件
1.Write-Ahead logs
HBase的修改记录,当对Hbase读写数据的时候,数据不是直接写进磁盘的,它会在内存中保留一段时间。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件当中,然后再写入内存中,所以在系统出现故障的时候,数据可以通过日志文件重建数据
2.HFile
这是在磁盘上保存原始数据的实际物理文件,是实际的存储文件
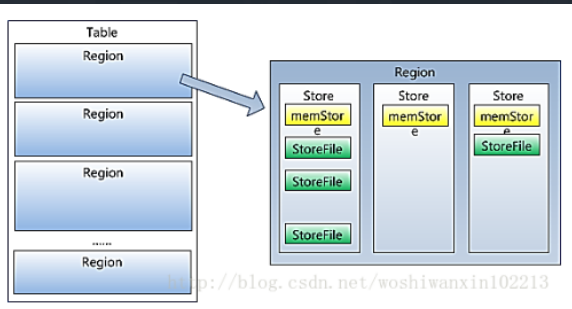
3.Store
HFile存储在Store中,一个Store对应HBase表 中的一个列族。
4.MemStore
内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在Write-Ahead-Logs中会后,RegionServer会在内存中存储键值对
5.Region
Hbase表的分片:Hbase表会根据RowKey值的不同,被切分成不同的region,存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
HBase架构
Hbase之所以可以很快的进行读写操作
是因为以空间换时间。 Hbase所进行的命令操作,会一开始存放在内存当中,当达到一定峰值64M/128M的时候会提交进磁盘当中。且也在写入内存之前,先写入log当中,以防宕机数据丢失,log是顺序读写,因此也不占性能,很快。
下图为Hbase架构图
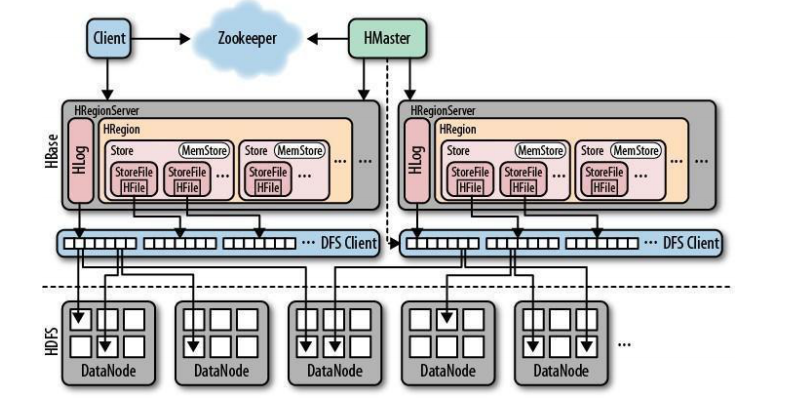
HBase 数据结构
Row Key
Row key是用来检索记录的主键。
访问HBASE table中的行,只有三种方式:
- 通过单个row key 访问
- 通过row key 的range(正则访问)
- 全表扫描
Row key保存为字节数组,存储时,数据按照Row key的字典序排序存储,
Ps.设计Row key时,将经常一起读取的行存储在一起(位置相关性)
Hbase Rowkey设计
在hbase当中rowkey是唯一的索引
a. 将经常需要查询的条件,放入rowkey中
b. hash rowkey为了避免读写热点
rowkey=hash(userkey)+userkey
反转rowkey reverse(rowkey)
ps:随机数不行,查询时无法获取
Columns Family
列族:Hbase表中的每个列都属于某个列族,列族想相当于一些列的map集合,列族是表的schema的一部分(而列不是),必须在使用表之前定义,列名都以列族作为前缀。
Cell
由{row key,columnFamily,version} 唯一确定的单元
- HBase中通过row和columns确定的唯一一个存贮单元称为cell。
- 由{row key, column(=
+ - cell中的数据是没有类型的,全部是字节码形式存贮。
- 每一个cell可以存储多个数据。
TimeStamp
Hbase中通过rowkey和columns确定的唯一一个存贮单元成为cell。每个cell都保存着同一份数据的多个版本(创建表的时候可以设定版本数量,当存储相同列数据时,显示出来的是按照时间戳排序显示最新put的数据)。版本同构时间戳来索引,时间戳的类型是64位整型。
为了避免数据存放过多版本造成管理负担,Hbase提供了两种数据版本回收方式。
- 一是保存数据的最后N个版本,
- 二是存储一段时间内的版本。用可针对每个列族进行设置

###hbase 预分区
默认情况下,hbase会为了新创建的表创建一个region。因此会带来热点问题。
可通过在创建表的时候,指定多个region解决热点问题。
方法有两种:
- 命令方式:create ‘t2’,’cf1’,SPILTS=>[‘b’,’c’,’d’,’e’]
- 代码方式:
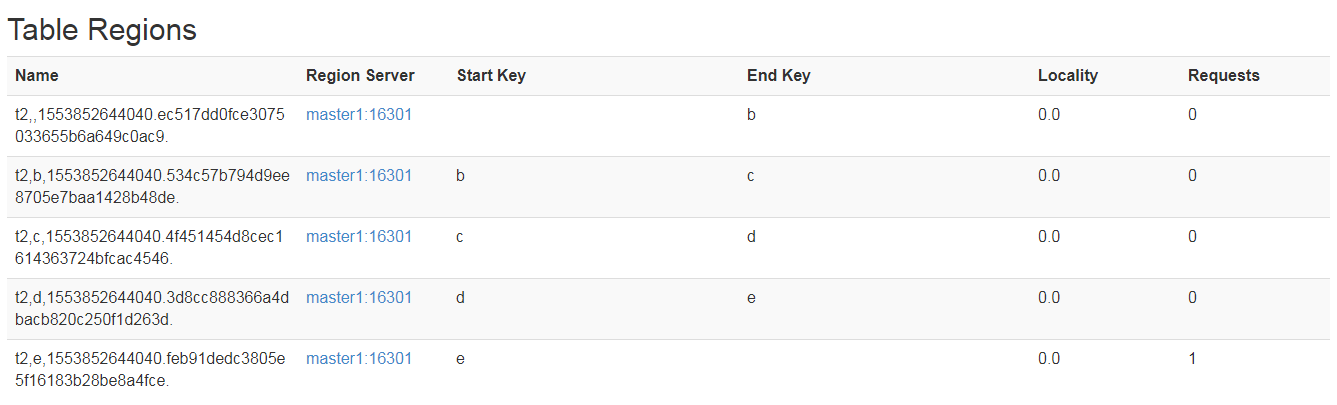
HBase索引
Row key 唯一的一级索引;
因此对于列值的查询,只能扫描全表,效率低。
因此可以借助:
- hbase 协处理器
- solr 分布式索引
实现二级索引:使用协处理器,将需要的二级索引和一级索性 处理成 二级索引对应所有的一级索引,然后由solr分布式索引存储,以备使用
协处理器(coprocesser)
触发器 (trigger)当我们在进行某些操作如增删改查的时候,执行的某个操作
当向Hbase进行写操作的时候,使用触发器进行中途拦截,触发-预处理-实现二级索引的实现
a. 继承BaseRegionObserver
b. 重写preput,predelete方法
c. 打包上传hbase lib 目录
d. 为表添加协处理器
1 | alter 't3','coprocessor'=>'/develop/hbase/hbase-1.4.8/lib/hbasedemo-1.0-SNAPSHOT.jar|com.demo.SecondIndexObserver|1001|' |
Hbase安装与使用
Hbase 伪分布部署
伪分布模式需要用到hadoop文件系统 ,所以配置会比单机模式麻烦很多
(1)、修改conf/hbase-env.shexport HBASE_CLASSPATH=/home/lin/hadoop/hadoop-2.6.1/etc/hadoop
(2)、编辑hbase-site.xml
hbase.rootdir 要配置为hdfs上的路径;hdfs://master:9000/hbase
1 | <property> |
(3)、启动hbase
1 | bin/start-hbase.sh |
jps
出现三个H开启的进程则ok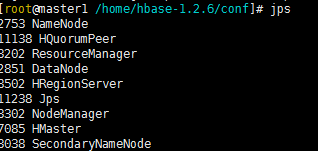
然后就可以进入shell进行对hbase的操作。
1 | bin/hbase shell |
Quick Start(Shell操作)
create 'test','cf1','cf2'
创建表test 列族cf1,cf2
list
查看表
describe 'test'
查看表test结构
put 'test','jack','cf1:age','18'
根据表名、行键以列族进行插入某行数据
get 'test','jack'
根据键值查询数据 只能查一行
get 'test','jack','cf1:name'
根据列族中的列查询数据 只能查一行
scan 'test'
扫描全表数据
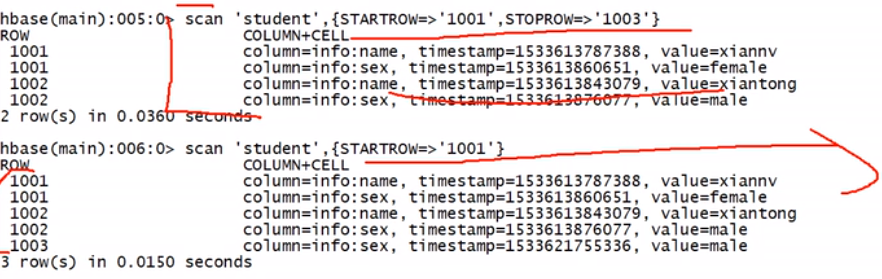
scan 'test',{STARTROW=>'jack'}
从头开始扫描rowkey为jack的行的数据
count 'test'
读取表数据行数
deleteall 'test','jack'
删除某rowkey的全部数据
delete'test','jack','cf1:name'
删除某rowkey的某一列数据
disable 'test'truncate 'test'
清空表数据(清空标的操作顺序为先disable,然后再truncate)
disable 'test'drop 'test'
删除表,也要先让表处于disable状态才能删除
create 'test' ,{name=>'cf1',versions=>3}
创建test表 列族名为cf1并存放在3个版本里
alter 'student',{Name=>'cf1',versions=>3}
修改表的信息:将cf1列族的数据存放在3个版本里
修改我的我
tips:HBase只支持单行事务,也就是说对一行数据进行修改的时候会对行进行锁定,不想sql可以进行多行锁定
Zookeeper 存储了 Hbase元数据的位置
Hbase的元数据存放在自己身上,我们通过连接Zookeeper获取HBase元数据在HBase的位置,
Hmaster管理表-增删改查
RegionServer具体管理表的读写
Store是由Region创建
HBase API
Hbase读写扫描
pom.xml加入依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.6</version>
</dependency>配置Hbase.properties
hbase.master=192.168.200.129:60000
hbase.zookeeper.quorum=192.168.200.129
添加config类
1 | public class Config { |
读写、批量写入、扫描查询
1 | package com.zhiyou100.kafka.Hbase; |
HBase过滤器
同上配置的config类,在此不做详解
下列为过滤指定的列以及列族,类似于查询条件语句
1 | public class HbaseFilterDemo { |
JAVA 第二索引的配置及使用方法
加依赖
1 | <dependency> |
1 |
|
做好之后,打包 放入Hbase文件夹中(注意如果放入HBase lib中,运行alter时报错无法找到此文件的话,就上传jar包至Hdfs一定可以)
然后再
创建